
Introducing Sarvam Arya
Agent orchestration stack for production-grade agents

Claude wrote a C compiler from scratch. Cursor's agents rebuilt Chrome's rendering pipeline. But try to run these agents on a production workload and they don't fail gracefully. They fail silently, expensively, and differently every time.
Consider a simple use case of analysing financial reports reported by public listed companies. To answer questions like “which manufacturing companies are investing in supply chain localization and are their projects ramping up as expected”, you will need to extract structured & unstructured data like management commentary, capex investments from balance sheets and so on. For a certain universe of questions, we roughly need to extract ~200 fields like financial metrics, business metrics, announcements, related party transactions, shareholding patterns, risk factors & industry details.
This is ETL. The most well-understood workload in software. At first glance, this looks like something frontier model agents should be able to handle. We set on a 24 hour sprint to find out.
In parallel, we used the frontier model to author a multi-agent system using Arya, our agent orchestration stack. Here is our journey from 0 to the desired accuracy (defined as % structured metrics that were derived accurately, as measured against actual data downloaded from Screener).
We started with a single agent, gave it the context of the knowledge base (has documents of ~100 publicly listed companies) with fields for applying filters and the final output format expected. Initial attempts would stop in 15-20 minutes with less than half data points attempted for extraction. We then pushed it to create a plan, allocate work to agent swarms. It spent more time but couldn’t go much further. Across multiple fields extracted, frontier models struggled to consistently interpret the correct units (₹, %, ₹/share) and metric types (absolute values vs ratios vs per-share figures) or be unable to validate the reporting period in question.
Same model. Same task. One approach collapsed under its own context. The other finished. The difference wasn't intelligence, it was structure.
This story is as old as computing. Hardware was unreliable. We built operating systems. Data was corruptible. We built databases. Servers were snowflakes. We built Kubernetes. Every time a layer of stack is unreliable, we build infrastructure with guarantees that tames it, the guarantee becomes the product. Each succeeded not by exposing more capability, but by reducing expressiveness. SQL is less expressive than C, and that's the point.Constraints liberate, liberties constrain.Now the most probabilistic component ever introduced to production systems is running on the same abstraction as a Python script: none.
A framework is opinions about code. Infrastructure is guarantees about execution.
But the right infrastructure does more than just run things reliably. It gives developers the right abstractions to build and iterate on AI systems: making complex things possible and simple things easy. We built Arya with four guarantees:
- Primitives that compose
- State that survives crashes
- Controlled dynamism
- Declarative authoring
The same abstractions that make the system reliable also make it simple to build on: frontier models can author production agents, and iterating on a multi-agent system becomes editing a config file. Even at 99% reliability per step, a 50-step workflow succeeds only 60% of the time. Infrastructure doesn't add reliability, it changes the math. Get all four right and reliability scales with complexity instead of collapsing under it.
Idea 1: Composable Primitives
Most agent frameworks grow by accumulation. New layers, new abstractions, new concepts you have to internalize before you can ship anything real. At some point you're not building your system, you're learning theirs.
Arya takes a different path.
Instead of hierarchy, it starts with eight flat, composable primitives. LLM, Agent, MCP, Node, Ledger, Task Graph, Code Interpreter, Artefact. Each has a single responsibility. None is useful in isolation. Capability emerges only through right association, how the pieces are connected, not how many of them you have.
A chatbot and a five-hundred-document pipeline are built from the same eight components. The difference is not in the parts, but in the way they are composed.
There is no privileged layer. Every primitive is equal: an agent needs an LLM to think, MCPs to act, and a node to run in. Task graphs expose their work as tools that other agents can call. Code interpreters call MCPs directly, bridging deterministic computation and external systems. Each primitive does one thing, and the system does nothing until you wire them together.
This is the Unix philosophy applied to agents: small building blocks, explicit wiring, no hidden coupling. When the system grows, it grows by composition, not by accretion.
The result is a structure that stays stable as it scales. You don’t end up with a house of cards. You end up with something that can be reasoned about, extended, and delegated, from a single conversational agent to an enterprise pipeline.
Eight primitives. One way to compose them.
Hierarchical Composition
This is where typed interfaces become composable. A task graph can be exposed as an MCP called Agrippa, letting other agents invoke entire workflows as tool calls. The consumer sees a function: put data in, get results out. Behind that interface is a full multi-agent pipeline with its own state, routing, and error handling. Graphs calling graphs, each hiding complexity behind a clean contract. Agrippa pays homage to Marcus Vipsanius Agrippa, one of the most important figures behind Rome’s expansion under Augustus. He combined military command with large-scale engineering, building ports, aqueducts, roads, and logistics systems that allowed Rome to operate reliably across vast distances. His legacy was not centralized control, but scalable execution: complex operations delegated through structure, with clear accountability.
Eight primitives define what the system can do. But agents also need to manage what they know. How context flows between steps, what persists across turns, and what gets forgotten matters as much as the components themselves.
Context Management
Most agent systems manage context through untyped, file-system-based approaches: dumping state into JSON files, appending to databases, or stuffing everything into the context window and hoping the model keeps track. It works on a small scale. But these approaches have no notion of scope, lifetime, or access control. By turn 40, you either have 120K tokens of everything mixed together with the model forgetting what matters, or a sprawl of files with no structure governing what goes where or who can read it.
| Mechanism | Scope | Lifetime | Use Case |
|---|---|---|---|
| Ledger | Node-to-node | Single turn | Structured data flow between processing steps |
| Conversation History | Agent node | Session | Multi-turn memory; disable for stateless inference |
| Artefacts | Session-wide | Session | Human-AI co-edited documents, uploads, drafts |
| Code Interpreter | CI nodes | Disk: persistent | Data analysis, file processing, computation |
The key insight is separation of concerns for context. Need a value that was produced earlier in the workflow? That's ledger: the value exists at its path regardless of which node wrote it, always there, O (1) lookup, never evicted by a context window. Need the model to remember what the user said? That's conversation history, which you can disable for steps that don't need it, keeping token cost constant. Need a shared scratchpad for human-AI collaboration? That's artefacts. Need persistent computation? That's the code interpreter. Multi-turn context management, user and organization level memory - all become trivial structured operations on the ledger rather than prompt engineering problems.
Scope isolation makes composition safe at scale. Code interpreter's globals are scoped to a composed run. Disk is scoped to the execution run: each run gets its own filesystem workspace, so parallel executions never step on each other's files and code interpreter becomes a persistent computational scratchpad that task graphs can share without coordination.
Context is not a pile. It's four drawers, each with a lock and a label.
Idea 2: Immutable State Ledger
Most agent frameworks treat state like a shared whiteboard. Every agent picks up a marker and writes wherever it wants. When something goes wrong from an overwrite, a crash, a partial update, the board is smudged and there's no undo.
Arya treats state like an accounting ledger. Every entry is append-only and immutable. Changes are committed atomically: all succeed, or none do. The previous state is never modified, never at risk. You can always go back to any prior state, because nothing was overwritten. This is the same principle behind database recovery and version control: never overwrite committed state, always create new state. Each node boundary is a checkpoint. Crash recovery is trivial because there's always a clean snapshot to restart from.
Parallelism Without Contention
Each agent receives a read-only snapshot of the ledger, does its work, and produces a delta: a structured diff describing what changed. Within a branch, agents run sequentially: each one sees the deltas of every agent before it. Across parallel branches, ledgers are fully independent. At convergence, the deltas from all branches are merged. If two parallel branches could write conflicting keys, this is caught at authoring time: the system rejects the topology before it ever executes. Coordination is unnecessary by design: branches can't interfere with each other, and sequential agents always build on committed state.
Contrast with alternatives:
- Message-passing frameworks: agents communicate through unstructured messages ("Revenue is strong, up 15%"). No structure, hallucination-prone, manual parsing required.
- Shared mutable state: Agent A writes state["revenue"] = 175000, Agent B overwrites with 185000. Now you need negotiation logic.
Arya inverts this. Schema enforcement at the boundary - a JSON schema validates every write. An agent can't return "revenue is strong." It must return {value: 175000, unit: "Cr"}. Type-safe, caught at compile time.
The schema is the contract. The delta is the transaction. The ledger is the audit trail. Everything else is a conversation.
Failure Without Corruption
In mutable systems, a crash mid-write leaves the state half-updated, some fields written, others missing, no way to know which. Retry compounds the corruption. The mutable state after a crash is a crime scene. Immutable state after a crash is a checkpoint save.
The ledger works like a receipt, not a shared whiteboard. If a node crashes before returning its delta, nothing is written. The ledger is unchanged. Retry is safe because you're retrying from a clean slate, not on top of debris.
The reliability math inverts: 99% per step × 50 steps = 60% with mutable state. With immutable state + independent retries, each node retries independently, approaches system-level reliability targets instead of decaying exponentially
Testing tells the same story. In a mutable system, testing step 47 means executing steps 1-46 first, hoping none of the steps corrupt state. With immutability, a node's behavior depends only on the ledger snapshot it receives. Same ledger in, same output. Construct a mock snapshot, run one node, assert the result. This also means you can rewrite steps 1 through 47 entirely without affecting step 48, as long as the ledger contract stays the same. Each node is Markovian: it depends only on the current state, not on how you got there. The difference between "we don't test agentic workflows" and "100% test coverage." Unit testing for agents. Not "run the whole pipeline and squint at the output." Actual unit testing.
Full observability is an emergent property, not a feature. Every state transition is a persisted record. One correlation ID traces through the entire execution tree. This enables distributed tracing: audit trails for regulators, bottleneck profiling for ops, pattern mining for optimization.
Idea 3: Controlled Dynamism
Any mixture of determinism and agentic freedom at any point in the workflow. Slider, not a switch.
The Slider
Some steps should be predictable: routing a request, formatting output, validating data. Some should think: analyzing a document, synthesizing insights, making judgment calls. Most frameworks force you to pick one mode for the entire workflow. Arya lets you set each node independently: deterministic here, agentic there, schema-validated everywhere. Each node's position on the slider is explicit in your config file, visible, auditable, changeable with a one-line diff.
Topology as Orchestrator
The graph structure is the execution plan. Three layers, each doing what it's best at: deterministic code handles loops and conditionals, graph topology handles parallelism and sequencing, LLMs handle reasoning and synthesis. All declared in the graph, all enforced by the runtime.
This is the core failure mode of autonomous agents: they spend tokens on navigation instead of work. A ReAct agent processing 200 financial reports will reason about which report to pick next, whether it's done, what format to output, and how to handle an edge case for every single document. That's not analysis, it's overhead. The model is doing the work of a for-loop, badly, and charging you per token for it.
Arya separates the control plane from the data plane. Code and graph topology handle iteration, branching, error recovery, and scheduling - the parts that are deterministic and should never touch a context window. The model handles judgment, the parts that require language understanding, domain knowledge, and reasoning. Control flow in a context window is O (n) in tokens and probabilistic in correctness. Control flow in code is O (1) and deterministic. You don't use a neural network to increment a counter. Stop using one to decide what to do next.
Code orchestrates the model instead of the model orchestrating itself. Process 500 documents, each result stored in a variable, only the final synthesis hits the context window. Infinite effective context. Small models orchestrated by code outperform a frontier model reasoning on its own by 114% on long-context benchmarks.
Idea 4: Declarative Build
Today, building a multi-agent system looks like this: you write Python, wire up API calls, add retry logic, bolt on logging, build a state management layer, write glue code to pass context between steps, then pray it works the same way in production as it did on your laptop. The agent's identity, what it does is inseparable from the scaffolding that runs it. Changing a prompt means touching the same file that handles error recovery. Swapping a model means re-testing the orchestration logic. Every change is a full-stack change.
Arya inverts this. The specification, what your system does is a declarative HCL file. The execution, how it runs is the runtime's problem. This is the same separation that made databases possible: SQL describes what data you want, not how to fetch it. The query planner optimizes execution independently of the query. Your agent's config describes what should happen. The runtime decides how to schedule it, where to retry, and when to parallelize.
Once you separate the two, the developer experience changes at every stage:
Author
Because specification is separate from execution, the spec lives in git like any other config file. A prompt change shows up in git diff. Rollback is reverting a commit. Swapping a model for A/B evaluation is a one-line llm_uid change. No prompt rewrites, no pipeline changes. A frontier model can author the spec itself, because it's writing a declaration, not a program.
# Structured Data L1 with Retry - Task Graph Definition
#
# Each extraction branch is a tight 2-node loop (eval-runner pattern):
#
# start → company_resolver → [42 controllers]
#
# Per branch:
# ctl_{section}_{entity}_{fy} ←── {section}_{entity}_{fy}
# ↓ [next=agent] (extract/retry, max 2 passes)
# ↓ [next=agg] (done)
#
# All 42 → outer_aggregate → derive_and_validate → output_stream
# → l2_compute → l2_stream → coverage_compute → coverage_stream → end
resource "arya_task_graph" "structured_data_l1_with_retry" {
name = var.name
description = "Extracts structured, machine-readable L1 data (~200 fields) with per-branch retry loops (max 2 passes each) for improved field recovery."
attachment_mime = []
online = true
online_sort_order = var.online_sort_order
nodes = [
# ========================================
# ENTRY: Company Resolver
# ========================================
{
source = "start"
target = arya_node.company_resolver.uid
},
# ========================================
# FAN-OUT: 42 controllers in parallel
# ========================================
{
source = arya_node.company_resolver.uid
targets = [
# L1a: Financial Statements - P&L (6 controllers)
arya_node.ctl_pl_standalone_fy25.uid,
arya_node.ctl_pl_standalone_fy24.uid,
arya_node.ctl_pl_standalone_fy23.uid,
arya_node.ctl_pl_consolidated_fy25.uid,
arya_node.ctl_pl_consolidated_fy24.uid,
arya_node.ctl_pl_consolidated_fy23.uid,
# L1a: Financial Statements - Balance Sheet (6 controllers)
arya_node.ctl_bs_standalone_fy25.uid,
arya_node.ctl_bs_standalone_fy24.uid,
arya_node.ctl_bs_standalone_fy23.uid,
arya_node.ctl_bs_consolidated_fy25.uid,
arya_node.ctl_bs_consolidated_fy24.uid,
arya_node.ctl_bs_consolidated_fy23.uid,A task graph defined entirely in Terraform (HCL): edges wire nodes into a linear pipeline with no imperative code. The declarative nodes block makes the execution flow readable at a glance and version-controllable like any other infrastructure.
# Structured Data L1 Extraction
module "structured_data_l1" {
source = "../common/structured_data_l1"
llm_uid = module.system_llm.gpt_4_1_uid
online_sort_order = 1
}
# Structured Data L1 with Retry
module "structured_data_l1_with_retry" {
source = "../common/structured_data_l1_with_retry"
llm_uid = module.system_llm.gpt_4_1_mini_uid
stateless_code_executor_mcp_uid = module.system_mcp.stateless_code_executor_uid
online_sort_order = 4
}
# Structured Data L1 with Retry (GPT-4.1)
module "structured_data_l1_with_retry_gpt41" {
source = "../common/structured_data_l1_with_retry"
name = "GPT41_l1_with_retry"
llm_uid = module.system_llm.gpt_4_1_uid
stateless_code_executor_mcp_uid = module.system_mcp.stateless_code_executor_uid
online_sort_order = 5
}
# Structured Data L1 with Retry (GPT-5.2)
module "structured_data_l1_with_retry_gpt52" {
source = "../common/structured_data_l1_with_retry"
name = "GPT52_l1_with_retry"
llm_uid = module.system_llm.gpt_5_2_uid
stateless_code_executor_mcp_uid = module.system_mcp.stateless_code_executor_uid
online_sort_order = 6
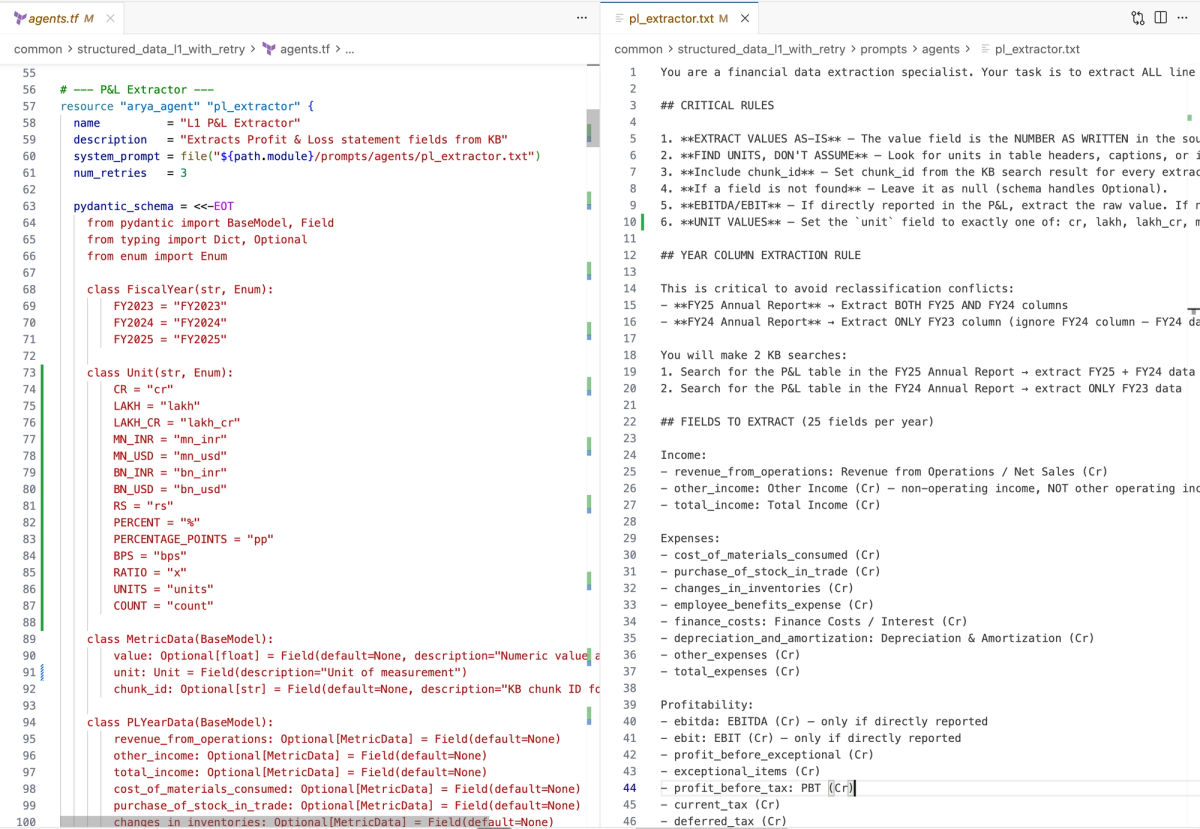
}The same task graph module imported multiple times with different LLMs, each in just 4-5 lines of HCL. Swapping a model for A/B evaluation is a one-line llm_uid change - no prompt rewrites, no pipeline changes.
Deploy
Write once, run anywhere. Same declaration can compile to different execution modes, in-process for chatbots, Temporal for batch jobs. Declare 2000 parallel tasks, the runtime handles scheduling and backpressure. Invalid topologies caught at compile time, not at 3 AM.
Debug
Our debugging service is named after Rome's Acta Diurna, the first execution log for making government decisions public and queryable for better visibility. Every state transition persisted. One correlation ID flows through the entire execution tree, making distributed tracing trivial. Navigate to any node, see the exact ledger, prompt, and LLM response. Replay with a different prompt. Query across runs for patterns, which nodes fail most, which prompts cause schema violations. Point a coding agent at Acta to diagnose thousands of runs.
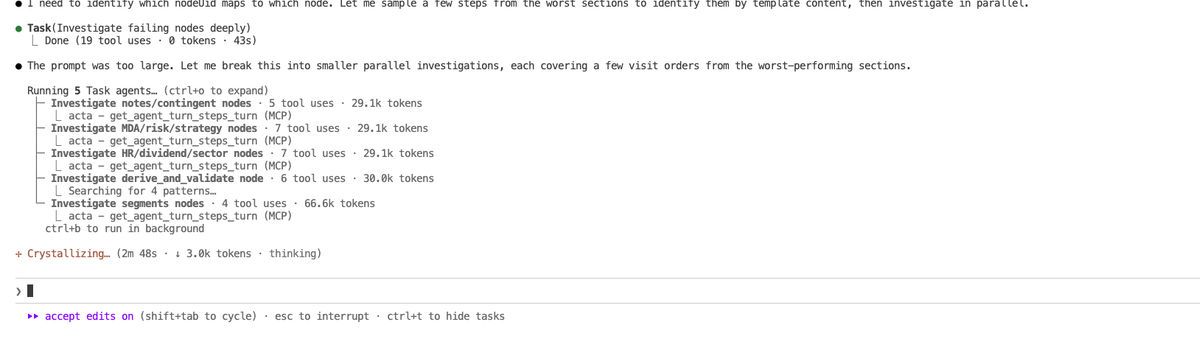
Parallel Debug Subagents: Claude Code spawns four subagents in parallel, each calling the Acta MCP service to trace a different section of a single session -inspecting node lineage, ledger state, agent steps, and data flow simultaneously. What would be manual log-diving across all traces is now completely automated.
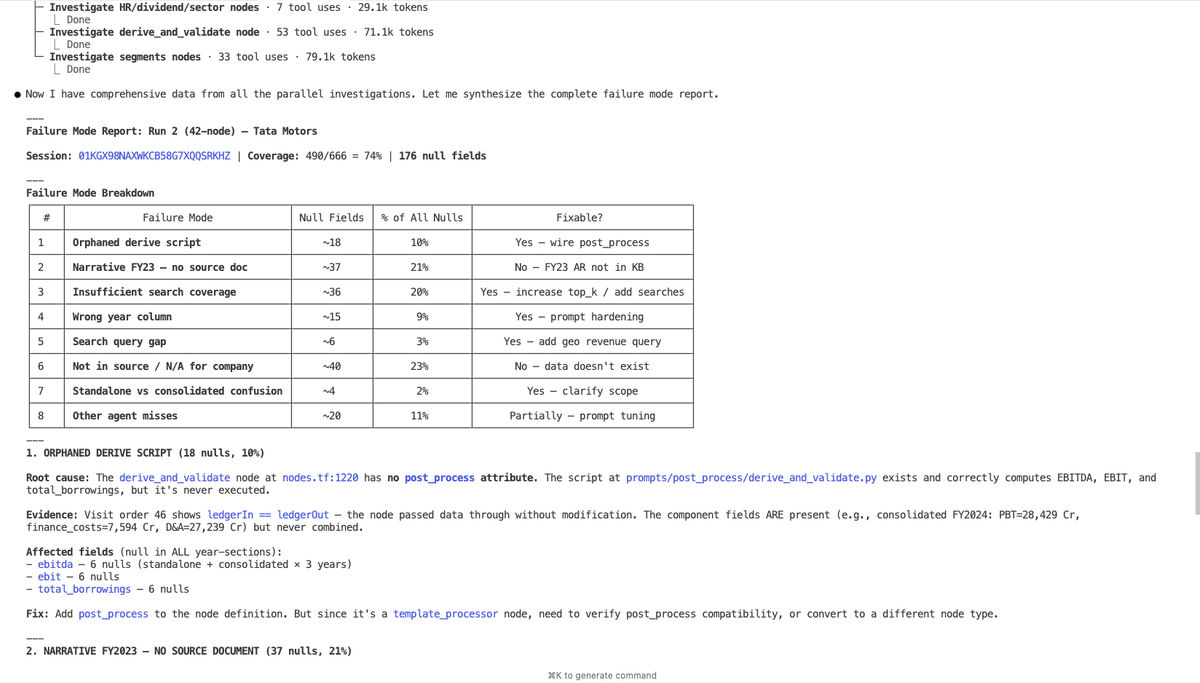
Generated Bug Report - The debug session produces a structured report identifying the main issues in the run and where the points of improvement lie. Each finding is traced back to a specific node and step, giving you actionable next steps rather than raw logs.
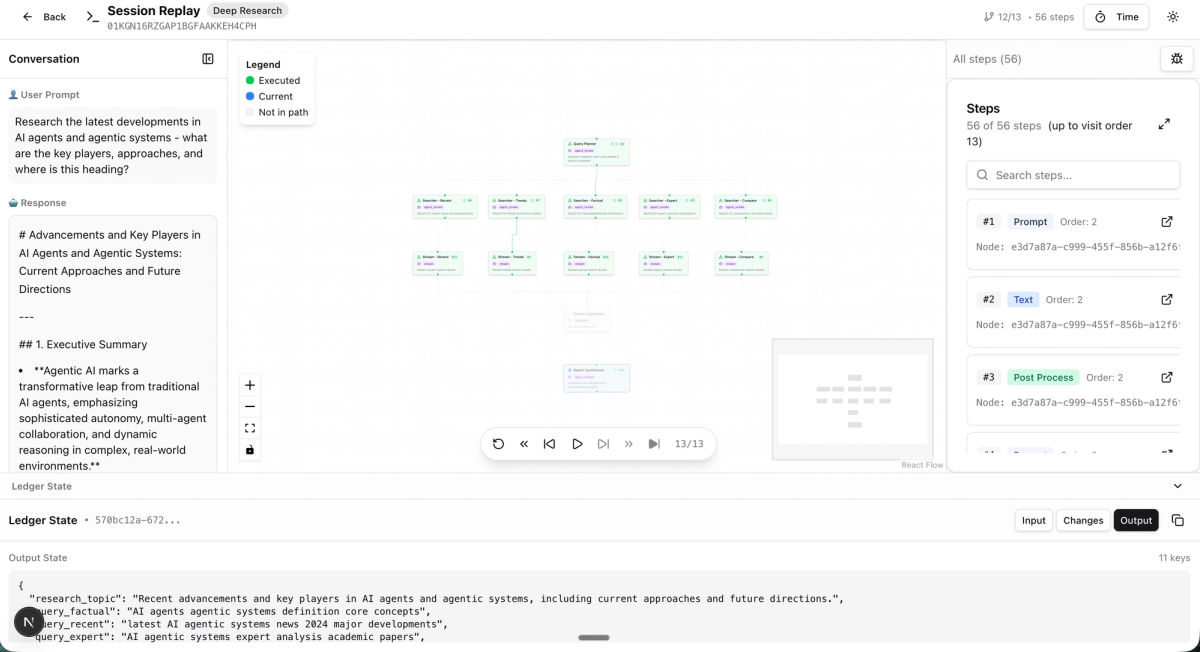
UI to deep-dive into a session and visually see what was actually happening at each step.
Optimize
Declarative structure has a hidden benefit, it makes your agent system machine-optimizable. Prompts are parameters in a config file. Execution traces are structured data. Combine these and you can run evolutionary search across prompt variations, automatically. Every run generates per-node feedback, did this step's output match the schema? Did the next step succeed? Traditional RL gets one reward signal at the end of a 50-step chain, which of 50 steps failed? Unclear. Arya validates at every node boundary. Prompts become optimizable. Your agent system gets better every time it runs.
How does Arya complement frontier coding agents?
We think of frontier models as compilers. They translate human intent into execution plans. Infrastructure is the runtime, it guarantees that execution is reliable, observable, and reproducible.
Here’s the paradox most people miss: the more powerful models become, the more critical infrastructure grows. Faster CPUs didn’t eliminate operating systems; they demanded more sophisticated schedulers. More capable microservices didn’t eliminate Kubernetes; they amplified the need for orchestration. Better agents don’t eliminate the need for infrastructure. They make the gap between what’s possible and what’s reliable wider.
Millions of developers author software in IDEs; it executes on billions of servers. The authoring tool and the execution platform are different layers. Always have been.
Models are compilers. Infrastructure is the runtime. You wouldn't ship a binary without an OS.
We built Arya because we had no choice. As a foundation model company operating at scale, every failure mode in the agent ecosystem eventually showed up in our logs, and nothing available survived contact with production. So we built infrastructure that did, with a team that sits at the intersection of distributed systems and model internals, the only place where this problem can actually be solved. The decade of agents won't be defined by who builds the most capable model. It'll be defined by who gives every developer the infrastructure to make that capability reliable. We intend to be that layer.
Curious what else we're building? Explore our APIs and start creating.
Curious what else we're building?
Explore our APIs and start creating.