
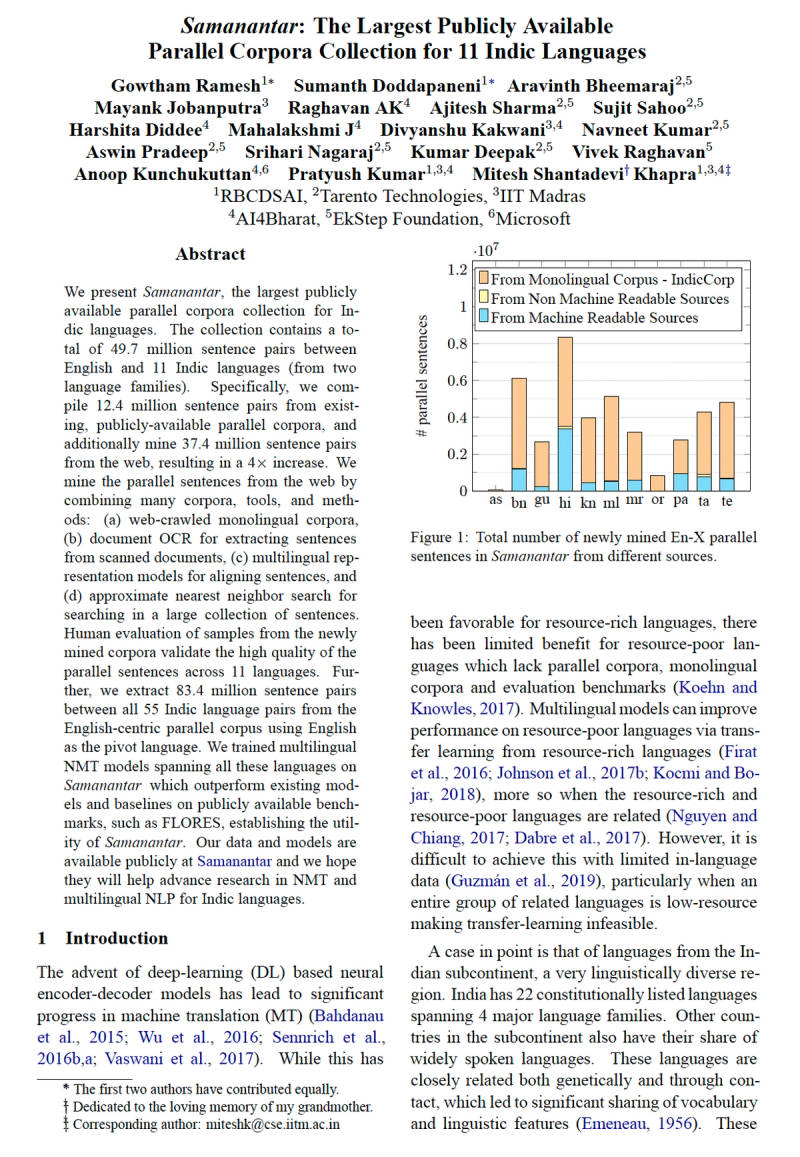
Sarvam Translate
Sarvam-Translate, an open-weights model, supports translation across 22 Indian languages with structured long-form text.

Now supporting 22 Indian languages and structured long-form text
Download the model from Hugging Face, try it on our
playground, and build with our
APIs.
Making content available across languages has been a key consideration for digital accessibility. While translation systems have continued to evolve, there remains work to be done in three broad directions - one, support for more languages; two, support for more natural translation of stylised (such as idiomatic) long-form text; and three, support for structured text in different formats. These formats could be varied depending on the source such as a math textbook with equations, or a web page with HTML code around content, or an output of digitising an image with potential OCR-related errors.
Although multilingual large language models have demonstrated the ability to do long-form translation, their performance on Indian languages still trails behind. At Sarvam, we’re working to address this by focusing on the 22 Scheduled Indian languages, with an emphasis on more natural translation while supporting long-form structured content.
We are happy to share that,in partnership with AI4Bharat,we have made a significant step forward in this with our latest model, Sarvam-Translate. Trained by fine-tuning Gemma3-4B-IT, Sarvam-Translate supports 22 Indian languages - Hindi, Bengali, Marathi, Telugu, Tamil, Gujarati, Urdu, Kannada, Odia, Malayalam, Punjabi, Assamese, Maithili, Santali, Kashmiri, Nepali, Sindhi, Dogri, Konkani, Manipuri (Meitei), Bodo, Sanskrit. It supports paragraph-level translation for 22 languages, and supports translating diverse structured content for 15 languages.
In human evaluation by language experts, Sarvam-Translate is identified to be significantly better than much larger models such as Gemma3-27B-IT, Llama4 Scout, and Llama-3.1-405B-FP8. Further, in automated evaluation on ability to conform to structured long-form content, Sarvam-Translate shows high accuracy (> 4.9 over 5) for 15 languages.
Sarvam-Translate is available to try out and use in your applications on our API store. Further, to enable others to use and build upon the model, we are releasing an open-weights model on
Hugging Face. This continues our commitment to build in the open for enabling a sovereign AI ecosystem for India. Example Use-Cases of Sarvam-Translate
Below is a feature matrix for each language supported by Sarvam-Translate.
| Language | Sentence | Paragraphs | Structured Document |
|---|---|---|---|
| Hindi | ✅ | ✅ | ✅ |
| Bengali | ✅ | ✅ | ✅ |
| Marathi | ✅ | ✅ | ✅ |
| Telugu | ✅ | ✅ | ✅ |
| Tamil | ✅ | ✅ | ✅ |
| Gujarati | ✅ | ✅ | ✅ |
| Urdu | ✅ | ✅ | ✅ |
| Kannada | ✅ | ✅ | ✅ |
| Odia | ✅ | ✅ | ✅ |
| Malayalam | ✅ | ✅ | ✅ |
| Punjabi | ✅ | ✅ | ✅ |
| Maithili | ✅ | ✅ | ✅ |
| Assamese | ✅ | ✅ | ✅ |
| Sanskrit | ✅ | ✅ | ✅ |
| Santali | ✅ | 🟨 | ❌ |
| Kashmiri | ✅ | 🟨 | ❌ |
| Nepali | ✅ | ✅ | ✅ |
| Konkani | ✅ | ✅ | 🟨 |
| Sindhi | ✅ | 🟨 | 🟨 |
| Dogri | ✅ | 🟨 | ❌ |
| Bodo | ✅ | 🟨 | 🟨 |
| Manipuri | ✅ | 🟨 | ❌ |
Language Support Feature Matrix
Example Use-Cases of Sarvam-Translate
Below, we share examples to highlight the different ways in which Sarvam-Translate could be used.
Translating web pages without breaking the HTML structure
Instead of extracting/reinserting text around tags, Sarvam-Translate preserves the HTML structure and only translates the visible text content.
Translating web content is one of the central use-cases of translation models. However, extracting, translating, and reinserting text is often error-prone and tedious. Sarvam-Translate streamlines this by translating only the visible textual content, preserving all HTML tags and structure. As seen in the image below various elements including emphasis etc are maintained in the text.
Source PDF

Translations
Translating LaTeX documents while preserving syntax
Academic and technical documents in LaTeX combine human-readable text with formatting and command syntax. Maintaining the integrity of LaTeX code during translation is challenging. Sarvam-Translate identifies and translates only the human-readable content while preserving LaTeX syntax and structure. In the example below tables, and formatting are retained. Also notice the model's choice of retaining author names in cited papers in English.
English
Translations

Translating chemistry documents
Chemistry documents often mix specialised chemical notations and equations. Ensuring these remain unaltered during translation requires fine control. Sarvam-Translate accurately translates the surrounding text while preserving chemical equations and formatting. Also notation such as x and y are retained in Roman characters.
Before Image

Translations

Translating idioms, slang and cultural references
Idiomatic expressions, figures of speech, and culturally specific phrases often lose meaning when translated literally. We find that Sarvam-Translate often produces translations that preserve the original tone, intent, and nuance. Notice in the following how several idiomatic phrases are correctly translated. For example, 'being behind the eight ball' an analogy from the game of pool meaning being in trouble is translated appropriately as 'జయేష్ అప్పటికే చాలా కష్టాల్లో ఉన్నాడు' inTelugu.
Input
"The Last Straw"
It was a Monday morning, and Jayesh was already behind the eight ball. His alarm hadn't gone off, he'd spilled coffee on his only clean shirt, and to top it all off, his car decided to kick the bucket right outside his driveway.
"Figures," he muttered, throwing his hands up. "When it rains, it pours."
Jayesh worked as an assistant manager at a downtown hardware store, and today was make-or-break. The regional manager was coming by, and if Jayesh didn't put his best foot forward, he'd be out on his ear.
By the time he arrived-twenty minutes late and sweaty as a pig in July-his boss, Lalita, was already breathing down his neck.
"You're skating on thin ice, Jayesh," she warned. "One more slip-up, and you're toast."
Jayesh bit his tongue. He needed this job. Rent wasn't going to pay itself, and with the way things were going, he was already robbing Pradeep to pay Pavan.
To his credit, Jayesh kept his nose to the grindstone all day. He bent over backwards to make sure everything ran like clockwork. The store looked like a million bucks. Even Lalita raised an eyebrow.
"Not bad," she said. "Maybe you're not such a lost cause after all."
Jayesh exhaled, finally feeling like he could see the light at the end of the tunnel.
But just as he started to breathe easy, disaster struck. A kid knocked over a shelf of paint cans, turning aisle seven into a rainbow swamp. Jayesh rushed over, only to slip and fall flat on his back-right in front of the regional manager.
That was the last straw.
Lalita helped him up, trying not to laugh. "Well, if you're gonna go out, might as well go out with a splash."
Jayesh blinked, half-expecting to get the axe then and there. But to his surprise, the regional manager chuckled.
"Hey, at least he's hands-on."
Jayesh cracked a grin. Maybe, just maybe, things were finally turning around.
"ది లాస్ట్ స్ట్రా"
అది ఒక సోమవారం ఉదయం, జయేష్ అప్పటికే చాలా కష్టాల్లో ఉన్నాడు. అతని అలారం మోగలేదు, తనకున్న ఒకే ఒక్క శుభ్రమైన చొక్కాపై కాఫీ చిందించాడు, అంతేకాకుండా అతని కారు అతని ఇంటి ముందున్న డ్రైవ్వేలో పేలిపోయింది.
"అవును," అని అతను విసుక్కుంటూ చేతులు పైకెత్తాడు. "అన్నీ ఒకేసారి జరిగాయి."
జయేష్ డౌన్టౌన్ హార్డ్వేర్ స్టోర్లో అసిస్టెంట్ మేనేజర్గా పనిచేసేవాడు, ఈ రోజు చాలా కీలకం. రీజినల్ మేనేజర్ వస్తున్నారు, జయేష్ తన శాయశక్తులా ప్రయత్నించకపోతే, అతను ఉద్యోగం కోల్పోతాడు.
అతను వచ్చే సమయానికి - ఇరవై నిమిషాలు ఆలస్యంగా, జూలై నెలలో ఎంతో చెమటలు పడుతూ - అతని బాస్ లలిత అప్పటికే అతని వెనుక ఉండి ఊపిరి పీల్చుకుంటోంది.
"జయేష్, నువ్వు ప్రమాదంలో ఉన్నావు," అని ఆమె హెచ్చరించింది. "మరో పొరపాటు జరిగితే, అంతే సంగతులు."
జయేష్ తన నాలుకను బిగించాడు. అతనికి ఈ ఉద్యోగం చాలా అవసరం. అద్దె కూడా సరిపోవడం లేదు, పరిస్థితులు చూస్తుంటే పవన్కు డబ్బులు ఇవ్వడానికి అతను ప్రదీప్ను దోచుకుంటున్నాడు.
అతని అదృష్టం బాగుంది, జయేష్ రోజంతా శ్రద్ధగా పనిచేశాడు. ప్రతిదీ సక్రమంగా జరిగేలా చూసుకోవడానికి తన శక్తి మేరకు ప్రయత్నించాడు. ఆ దుకాణం చాలా అందంగా కనిపించింది. లలిత కూడా ఆశ్చర్యపోయింది.
"మరీ చెడ్డగా లేదు," అని ఆమె అంది. "బహుశా నువ్వు ఇంకా పనికిమాలిన వాడివి కాకపోవచ్చు."
జయేష్ ఊపిరి పీల్చుకున్నాడు, చివరకు ఏదో ఒక వెలుగు కనిపిస్తున్నట్లు అనిపించింది.
అతను ఊపిరి పీల్చుకోవడం మొదలుపెట్టగానే, ఒక విపత్తు సంభవించింది. ఒక పిల్లవాడు పెయింట్ డబ్బాల అరను పడగొట్టాడు, ఏడవ వరుసను ఇంద్రధనస్సులా మార్చాడు. జయేష్ వెంటనే అక్కడికి పరిగెత్తాడు, కానీ కాలు జారి వెనక్కి పడ్డాడు - అది కూడా రీజినల్ మేనేజర్ ముందు.
అది చివరి గడ్డిపరక.
లలిత నవ్వకుండా అతన్ని లేవనెత్తింది. "సరే, నువ్వు బయటికి వెళ్లబోతున్నావు, కాబట్టి ఒక పెద్ద శబ్దంతో వెళ్లవచ్చు."
జయేష్ కళ్ళు తెరిచాడు, వెంటనే ఉద్యోగం పోతుందేమో అని అనుకున్నాడు. కానీ ఆశ్చర్యకరంగా, రీజినల్ మేనేజర్ నవ్వింది.
"హే, కనీసం అతను పనిలో శ్రద్ధగా ఉన్నాడు."
జయేష్ చిరునవ్వు నవ్వాడు. బహుశా, పరిస్థితులు చివరకు మారుతున్నాయేమో.
Translating folk tales while preserving cultural nuance
Narrative text such as folk tales and fiction carries cultural depth and stylistic nuance. Capturing this while maintaining readability across languages is complex. Our model handles narrative flow, cultural expressions, and stylistic elements to produce faithful translations. For example, in Maithili the phrase "One who interferes in other's work" has been translated to "जे दोसरक काजमे टाँग अड़ाबैत अछि" which is an appropriate use of a common idiom.
Input
The Monkey and the Wedge
"One, who interferes in other's work, surely comes to grief".
There was once a merchant who employed many carpenters and masons to build a temple in his garden. Regularly, they would start work in the morning; and take a break for the mid-day meals, and return to resume work till evening.
One day, a group of monkey arrived at the site of the building and watched the workers leaving for their mid-day meals.
One of the carpenters was sawing a huge log of wood. Since, it was only half-done; he placed a wedge in between to prevent the log from closing up. He then went off along with the other workers for his meal.
When all the workers were gone, the monkeys came down from the trees and started jumping around the site, and playing with the instruments.
There was one monkey, who got curious about the wedge placed between the log. He sat down on the log, and having placed himself in between the half-split log, caught hold of the wedge and started pulling at it.
All of a sudden, the wedge came out. As a result, the half-split log closed in and the monkey got caught in the gap of the log.
As was his destiny, he was severely wounded.
The wise indeed say: One, who interferes in other's work, surely comes to grief.
বানর ও কীলক
"অন্যের কাজে হাত দিলে, সে তো বিপদে পড়বেই"।
একদা এক বণিকের বাগানে একটি মন্দির নির্মাণের জন্য অনেক কাঠমিস্ত্রি ও রাজমিস্ত্রিকে নিযুক্ত করেছিলেন। তারা নিয়মিত সকালে কাজ শুরু করতেন; এবং মধ্যাহ্নভোজনের জন্য বিরতি নিতেন, এবং সন্ধ্যায় আবার কাজে যোগ দিতেন।
একদিন একদল বানর নির্মাণস্থলের কাছে এসে দেখল শ্রমিকরা মধ্যাহ্নভোজনের জন্য চলে যাচ্ছে।
কাঠমিস্ত্রীদের একজন বিশাল একটি কাঠ কাটছিলেন। যেহেতু এটি কেবল অর্ধেক কাটা ছিল; তাই তিনি কাঠটিকে বন্ধ হওয়া থেকে আটকাতে মাঝখানে একটি কীলক বসিয়ে দিলেন। তারপর তিনি অন্যান্য শ্রমিকদের সাথে খেতে চলে গেলেন।
যখন সমস্ত শ্রমিক চলে গেল, বানররা গাছ থেকে নেমে এসে সাইটে লাফাতে শুরু করল, এবং যন্ত্রপাতির সাথে খেলা শুরু করল।
সেখানে একটি বানর ছিল, যে কাঠের মধ্যে রাখা কীলকটি সম্পর্কে কৌতূহলী হয়েছিল। সে কাঠের উপর বসে, এবং নিজেকে অর্ধেক কাটা কাঠের মধ্যে স্থাপন করে, কীলকটি ধরে টানতে শুরু করল।
হঠাৎ, কীলকটি বেরিয়ে এল। ফলে, অর্ধেক কাটা কাঠটি বন্ধ হয়ে গেল এবং বানরটি কাঠের ফাঁকে আটকা পড়ল।
ভাগ্যে তার যেমন ছিল, সে মারাত্মকভাবে আহত হয়েছিল।
জ্ঞানীরা সত্যিই বলেন: অন্যের কাজে হাত দিলে, সে তো বিপদে পড়বেই।
Translating social media posts with slang & emojis
Social media posts frequently contain informal language, slang, emojis, and unconventional structure, posing unique translation challenges. We find that Sarvam-Translate is often able to handle such content, accurately conveying both meaning and tone. Notice in the example below both usage of various emojis and stylised content. Example "Wut u doing rn?" is translated appropriately in Kannada as "ಏನ್ ಮಾಡ್ತಾ ಇದೀಯಾ?"
Input
@Alex_P: Yo bro! 👋 Wut u doin rn? I'm BORED 😩
@Jamie_B: Damn man! 😂 Same here! Just scrolling thru TikTok vids lol. Nothin much. U?
@Alex_P: Literally staring at my ceiling. 🙄 Thinking of ordering some food. Pizza? 🍕 Or maybe sushi? 🍣 SO indecisive! xD
@Jamie_B: Ooooh sushi sounds BOMB 💣. Get some for me too? Jk jk...
@Alex_P: Hahaha! 🤣 Tempting, very tempting! If u lived closer, I totally would. Maybe we plan a sushi night soon? For realz.
@Jamie_B: YASSSS! 🙌 I'm so down for that! Lemme know when. My schedule's p flexible next week. BTW, did u see that new meme with the cat? 😹
@Alex_P: The one with the confused face? 🤨 Bro, I DIED. Sent it to my sis and she was like "it's literally me". xD
@Jamie_B: Absolutely! 💀 Some ppl are so creative. Anyway, if u do get food, lmk what u decide! Don't wanna keep u from ur important ceiling-staring work. 😉
@Alex_P: Lol, roger that. 👍 Probably gonna go with pizza cuz it's easier. Less brain power needed. 🧠💥 Talk later, alligator! 🐊
@Jamie_B: Aight, conda! 🐍 Have fun! Ttyl 😊👋
@Alex_P: ಏಯ್ ಬ್ರೋ! 👋 ಏನ್ ಮಾಡ್ತಾ ಇದೀಯಾ? ನನಗೆ ಬೇಜಾರಾಗ್ತಿದೆ 😩
@Jamie_B: ಛೇ! ನನಗೂ ಅದೇ ಅನಿಸುತ್ತಿದೆ! ಟಿಕ್ಟಾಕ್ ವಿಡಿಯೋಗಳನ್ನು ನೋಡುತ್ತಿದ್ದೇನೆ. ಏನೂ ಇಲ್ಲ. ನೀನೇನು?
@Alex_P: ನಾನು ಅಕ್ಷರಶಃ ನನ್ನ ಸೀಲಿಂಗ್ ಕಡೆ ನೋಡುತ್ತಿದ್ದೇನೆ. 🙄 ಏನಾದರೂ ತಿಂಡಿ ಆರ್ಡರ್ ಮಾಡೋಣ ಅನ್ಕೊಂಡಿದ್ದೇನೆ. ಪಿಜ್ಜಾ? 🍕 ಅಥವಾ ಸುಶಿ? 🍣 ತುಂಬಾ ತೀರ್ಮಾನ ತೆಗೆದುಕೊಳ್ಳಲು ಆಗುತ್ತಿಲ್ಲ! xD
@Jamie_B: ಓಹ್, ಸುಶಿ ತುಂಬಾ ಚೆನ್ನಾಗಿರುತ್ತೆ 💣. ನನಗೂ ಸ್ವಲ್ಪ ತರಿಸಿಕೊ? ತಮಾಷೆ ಅಲ್ವಾ...
@Alex_P: ಹಹಹ! 🤣 ತುಂಬಾ ಆಸೆಯಾಗಿದೆ, ತುಂಬಾ ಆಸೆಯಾಗಿದೆ! ನೀನು ಹತ್ತಿರದಲ್ಲೇ ಇದ್ದಿದ್ದರೆ, ಖಂಡಿತ ತರಿಸುತ್ತಿದ್ದೆ. ಬಹುಶಃ ನಾವು ಶೀಘ್ರದಲ್ಲೇ ಸುಶಿ ರಾತ್ರಿಯನ್ನು ಯೋಜಿಸೋಣ? ನಿಜವಾಗ್ಲೂ.
@Jamie_B: ಸರಿ! 🙌 ನಾನು ಅದಕ್ಕೆ ಸಿದ್ಧನಿದ್ದೇನೆ! ಯಾವಾಗ ಅಂತ ಹೇಳು. ಮುಂದಿನ ವಾರ ನನ್ನ ವೇಳಾಪಟ್ಟಿ ತುಂಬಾ ಫ್ಲೆಕ್ಸಿಬಲ್ ಆಗಿದೆ. ಅಂದಹಾಗೆ, ಬೆಕ್ಕಿನ ಹೊಸ ಮೀಮ್ ನೋಡಿದೆಯಾ? 😹
@Alex_P: ಗೊಂದಲದ ಮುಖದ ಮೇಲಿನದು? 🤨 ಬ್ರೋ, ನಾನು ಸತ್ತೆ. ಅದನ್ನು ನನ್ನ ತಂಗಿಗೆ ಕಳುಹಿಸಿದೆ ಮತ್ತು ಅವಳು "ಅದು ಅಕ್ಷರಶಃ ನಾನೇ" ಎಂದಳು. xD
@Jamie_B: ಖಂಡಿತ! 💀 ಕೆಲವರು ತುಂಬಾ ಕ್ರಿಯೇಟಿವ್ ಆಗಿರುತ್ತಾರೆ. ಏನೇ ಆಗಲಿ, ನೀನು ಏನಾದರೂ ತಿಂಡಿ ತರಿಸಿದರೆ, ನೀನು ಏನು ನಿರ್ಧರಿಸುತ್ತೀಯೋ ನನಗೆ ನೆನಪಿರುತ್ತದೆ! ನಿನ್ನ ಮುಖ್ಯವಾದ ಸೀಲಿಂಗ್ ನೋಡುವ ಕೆಲಸದಿಂದ ನಿನ್ನನ್ನು ದೂರವಿಡಲು ನಾನು ಬಯಸುವುದಿಲ್ಲ. 😉
@Alex_P: ಲಾಲ್, ರೋಸರ್ ದಟ್. 👍 ಬಹುಶಃ ಪಿಜ್ಜಾ ತರಿಸುತ್ತೇನೆ ಏಕೆಂದರೆ ಅದು ಸುಲಭ. ಕಡಿಮೆ ಮೆದುಳಿನ ಶಕ್ತಿ ಬೇಕಾಗುತ್ತದೆ. 🧠💥 ಆಲಿಗೇಟರ್, ಆಮೇಲೆ ಮಾತನಾಡೋಣ! 🐊
@Jamie_B: ಸರಿ, ಕೊಂಡಾ! 🐍 ಮಜಾ ಮಾಡು! ಟಿಟಿವೈಲ್ 😊👋
Translating subtitle files while maintaining timing and formatting
Subtitle (SRT) files require precise alignment of translated text with timing and formatting cues. Our model translates only the spoken dialogue while maintaining subtitle structure and synchronization. This can enable a single API click to enable accessible SRT files.
Input
130 00:09:09,366 --> 00:09:12,133 This is the "Lex Fridman Podcast."
131 00:09:12,166 --> 00:09:17,000 And now, dear friends, here's the Prime Minister of India,
132 00:09:17,033 --> 00:09:18,733 Narendra Modi.
133 00:09:19,733 --> 00:09:21,633 So, I should also say, I'm fasting right now.
134 00:09:21,733 --> 00:09:24,433 It's been almost two days, 45 hours.
135 00:09:24,833 --> 00:09:29,333 So just water, no food, in honor of this conversation,
136 00:09:29,333 --> 00:09:33,133 just to get in the right mindset, get into the spiritual level.
137 00:09:33,333 --> 00:09:35,933 I've read that you often fast for many days.
138 00:09:36,333 --> 00:09:41,266 Can you explain why you fast and where does your mind go when you fast?
139 00:09:42,333 --> 00:09:49,166
- First of all, I'm truly, pleasantly surprised and honored that you're fasting.
140 00:09:50,133 --> 00:09:56,833 All the more because it feels like you're fasting as a tribute of respect for me.
141 00:09:57,966 --> 00:10:01,233 So I express my deepest gratitude to you for doing this.
142 00:10:03,266 --> 00:10:04,833 In India,
143 00:10:08,433 --> 00:10:11,333 our religious traditions
144 00:10:13,166 --> 00:10:16,433 are actually a way of life.
145 00:10:20,466 --> 00:10:26,900 Our Supreme Court once gave a brilliant interpretation of Hinduism.
146 00:10:28,166 --> 00:10:35,133 They have stated that Hinduism is not about rituals or methods of worship.
147 00:10:36,033 --> 00:10:41,066 But rather it is a way of living,
148 00:10:41,966 --> 00:10:44,233 a philosophy that guides life itself.
130 00:09:09,366 --> 00:09:12,133 बेयो "लेक्स फ्रिडमेन पडकास्ट"।
131 00:09:12,166 --> 00:09:17,000 आरो दा, अनजालि लोगोफोर, बेयाव दं भारतनि गाहाइ मन्थ्रि,
132 00:09:17,033 --> 00:09:18,733 नरेन्द्र मदि।
133 00:09:19,733 --> 00:09:21,633 बेनिखायनो, आं बेखौबो बुंनांगौ, आं दा उपबास खालामगासिनो दं।
134 00:09:21,733 --> 00:09:24,433 बेयो प्राय नै सान, 45 घन्टा जाबाय।
135 00:09:24,833 --> 00:09:29,333 बेनिखायनो खालि दै, आदार गैया, बे रायज्लायनायनि मानआव,
136 00:09:29,333 --> 00:09:33,133 थार सानस्रियाव थानो, आथमिक थाखोआव हाबनो।
137 00:09:33,333 --> 00:09:35,933 आं फरायदोंदि नोंथाङा गोबां खेब गोबां सानसिम उपास खालामो।
138 00:09:36,333 --> 00:09:41,266 नोंथाङा मानो उपास खालामो आरो नोंथांनि गोसोआ बबेयाव थाङो जेब्ला नोंथाङा उपास खालामो, बेखौ फोरमायनो हागोन नामा?
139 00:09:42,333 --> 00:09:49,166
- गिबियावनो, आं थारैनो, गोजोनथावैनो सोमोनांदों आरो मान होदोंदि नोंथाङा उपास खालामगासिनो दं।
140 00:09:50,133 --> 00:09:56,833 आरोबाव बांसिन मानोना बेयो मोनदाङोदि नोंथाङा आरोबाव आंनि थाखाय माननि उपासन महरै उपास खालामगासिनो दं।
141 00:09:57,966 --> 00:10:01,233 बेनिखायनो आं नोंथांनि बेखौ मावनायनि थाखाय गोथौसिन साबायखर बावो।
142 00:10:03,266 --> 00:10:04,833 भारताव,
143 00:10:08,433 --> 00:10:11,333 जोंनि धोरोमारि सोलिबोनायफोरा
144 00:10:13,166 --> 00:10:16,433 थारैनो मोनसे जिउ खुंनायनि राहा।
145 00:10:20,466 --> 00:10:26,900 जोंनि गोजौसिन बिजिरसालिया मोनसे समाव हिन्दु धोरोमनि जोबोद मोजां बिजिरथाइ होदोंमोन।
146 00:10:28,166 --> 00:10:35,133 बिसोर बुंदोंदि हिन्दु धोरोमा धोरोमारि नेम-खान्थि एबा सिबिनायनि राहाफोरनि सोमोन्दै नङा।
147 00:10:36,033 --> 00:10:41,066 नाथाय बेनि सोलायै बेयो मोनसे जिउ खुंनायनि राहा,
148 00:10:41,966 --> 00:10:44,233 मोनसे सानथौ जाय जिउखौनो लामा दिन्थियो।
Translating documents with embedded foreign-language text
Multilingual documents often contain embedded foreign-language text that in most situations is expected to remain untranslated. Sarvam-Translate demonstrates the ability to identify such segments and preserve them while translating surrounding content. In the example below, we have traditional Chinese characters which are preserved.
Input
Bodhidharma (菩提達摩)
Bodhidharma (菩提達摩) was a Buddhist monk believed to have lived during the 5th or 6th century CE. He is widely recognized as the founder of Chan Buddhism [禪宗] in China and is considered the first patriarch [初祖] of the tradition. According to Chinese sources, Bodhidharma came from the Western Regions [西域]-possibly from South India [南天竺]-and traveled to China to spread the teachings of dhyāna [禪那], or meditative Buddhism.
One of the most well-known legends involves his meeting with Emperor Wu of Liang [梁武帝]. When the emperor asked him what merit [功德] he had gained from his generous support of Buddhism, Bodhidharma famously replied, "None whatsoever [無功德]", underscoring the Chan emphasis on inner realization [自悟] rather than external acts [外相].
After the imperial encounter, Bodhidharma is said to have journeyed to the Shaolin Monastery [少林寺], where he meditated facing a wall [面壁九年] for nine years. During this period, he is believed to have introduced physical exercises [行功] to aid monks in their practice, which later evolved into Shaolin martial arts [少林功夫].
His core teaching, often summarized as:
"Direct pointing to the mind, seeing one's nature, and becoming a Buddha [直指人心,見性成佛]",
rejected reliance on scriptures [經典] and ritual [儀式], emphasizing sudden enlightenment [頓悟].
Bodhidharma is also associated with a key text called "Two Entrances and Four Practices [二入四行論]", where he describes two paths:
- The entrance of principle [理入], and
- The entrance of practice [行入], which includes:
- Acceptance of suffering [報冤行]
- Detachment from circumstances [隨緣行]
- Absence of craving [無所求行]
- Accordance with the Dharma [稱法行]
In Japan, he is known as Daruma [達磨] and remains a cultural icon, often depicted in Daruma dolls [達磨達磨] symbolizing perseverance [堅忍] and good fortune [福運].
বোধিধৰ্ম (菩提達摩)
বোধিধৰ্ম (菩提達摩) আছিল এজন বৌদ্ধ ভিক্ষু যাক খ্ৰীষ্টীয় পঞ্চম বা ষষ্ঠ শতিকাত বাস কৰিছিল বুলি বিশ্বাস কৰা হয়। তেওঁক চীনত চান বৌদ্ধ ধৰ্মৰ [禪宗] প্ৰতিষ্ঠাপক হিচাপে বহুলভাৱে স্বীকৃতি দিয়া হয় আৰু এই পৰম্পৰাৰ প্ৰথম পিতৃ [初祖] বুলি গণ্য কৰা হয়। চীনা উৎস অনুসৰি, বোধিধৰ্ম পশ্চিম অঞ্চল [西域]ৰ পৰা আহিছিল-সম্ভৱতঃ দক্ষিণ ভাৰত [南天竺]ৰ পৰা-আৰু ধ্যান [禪那] বা ধ্যানমূলক বৌদ্ধ ধৰ্মৰ শিক্ষা বিয়পোৱাৰ বাবে চীনলৈ গৈছিল।
তেওঁৰ আটাইতকৈ বিখ্যাত কিংবদন্তীসমূহৰ ভিতৰত এটা হ'ল লিয়াঙৰ সম্ৰাট ৱু [梁武帝]ৰ সৈতে তেওঁৰ সাক্ষাৎ। যেতিয়া সম্ৰাটে তেওঁক বৌদ্ধ ধৰ্মক উদাৰভাৱে সমৰ্থন কৰাৰ বাবে কি পুণ্য [功德] লাভ কৰিছে বুলি সুধিলে, তেতিয়া বোধিধৰ্মে বিখ্যাতভাৱে উত্তৰ দিলে, "একেও নহয় [無功德]", যাৰ দ্বাৰা চান ধৰ্মৰ বাহ্যিক কাৰ্য্যকলাপ [外相]ৰ পৰিৱৰ্তে আভ্যন্তৰীণ উপলব্ধি [self-realization]ৰ ওপৰত গুৰুত্ব আৰোপ কৰা হৈছিল।
সাম্ৰাজ্যিক সাক্ষাৎৰ পিছত, বোধিধৰ্মে শ্বাওলিন মঠলৈ [少林寺] যাত্ৰা কৰিছিল বুলি কোৱা হয়, য'ত তেওঁ ন বছৰ ধৰি এখন দেৱালৰ ফালে মুখ কৰি ধ্যান কৰিছিল। এই সময়ছোৱাত, তেওঁ ভিক্ষুসকলক তেওঁলোকৰ সাধনাত সহায় কৰিবলৈ শাৰীৰিক ব্যায়াম [行功] প্ৰৱৰ্তন কৰিছিল বুলি বিশ্বাস কৰা হয়, যি পিছলৈ শ্বাওলিন সমৰ কলা [少林功夫]লৈ বিকশিত হৈছিল।
তেওঁৰ মূল শিক্ষা, যাক প্ৰায়ে এনেদৰে সংক্ষিপ্ত কৰা হয়:
"পোনপটীয়াকৈ মনলৈ আঙুলিয়াই দিয়া, নিজৰ প্ৰকৃতি দেখা, আৰু বুদ্ধ হোৱা [直指人心,見性成佛]",
শাস্ত্ৰ [經典] আৰু ৰীতি-নীতিৰ [儀式] ওপৰত নিৰ্ভৰ কৰিবলৈ অস্বীকাৰ কৰিছিল, আৰু আকস্মিক জ্ঞান [頓悟]ৰ ওপৰত গুৰুত্ব আৰোপ কৰিছিল।
বোধিধৰ্মক "দুটা প্ৰৱেশ আৰু চাৰিটা অভ্যাস [二入Four Practices]" নামৰ এটা মূল গ্ৰন্থৰ সৈতেও জড়িত কৰা হয়, য'ত তেওঁ দুটা পথৰ বিষয়ে বৰ্ণনা কৰিছে:
- নীতিৰ প্ৰৱেশ [理入], আৰু
- অভ্যাসৰ প্ৰৱেশ [行入], য'ত অন্তৰ্ভুক্ত আছে:
- দুখৰ গ্ৰহণ [報冤Four Practices]
- পৰিস্থিতিৰ পৰা বিৰত থকা [隨緣Four Practices]
- কামনাৰ অনুপস্থিতি [無所求Four Practices]
- ধৰ্মৰ সৈতে মিল [稱法Four Practices]
জাপানত, তেওঁক দাৰুমা [達磨] নামেৰে জনা যায় আৰু তেওঁ এতিয়াও এক সাংস্কৃতিক আইকন, যাক প্ৰায়ে দাৰুমা পুতলাত [達磨達磨] চিত্ৰিত কৰা হয়, যি অধ্যৱসায় [perseverance] আৰু সৌভাগ্য [good fortune]ৰ প্ৰতীক।
Translating legal documents with precision
Legal texts demand high precision in terminology and structure. Translating such documents requires preserving legal references, clauses, and formatting. We find that Sarvam-Translate is able to ensure accuracy and consistency suitable for professional legal use. For example, consider the complex sentence "Upon a meticulous perusal of the statutory scheme, the legislative history of the Parent Act, and the precedents cited at the Bar, this Court is disinclined to accede to the appellant's submissions". The model is able to translate this in Assamese as "বিধিবদ্ধ আঁচনি, মূল আইনৰ বিধিবদ্ধ ইতিহাস, আৰু বাৰত উল্লেখ কৰা পূৰ্ব উদাহৰণসমূহৰ এক নিখুঁত পৰ্যালোচনাৰ পিছত, এই আদালতে আপীলকাৰীৰ যুক্তিসমূহ মানি ল'বলৈ অনিচ্ছুক" which is a more natural sentence structure and correctly conveys the technical content.
Input: Judgement Document
IN THE SUPREME COURT OF INDIA
CIVIL APPELLATE JURISDICTION
CIVIL APPEAL NO. XXXX OF 2023
Poko Corporation Ltd. ... Appellant
Versus
Union of India & Anr. ... Respondents
J U D G M E N T
[Coram: Hon'ble Mr. Justice Kalyan Jyoti Sengupta, Hon'ble Ms. Justice Anjali Gagnani]
-
The present appeal, preferred under Article 136 of the Constitution of India, assails the correctness and legal sustainability of the impugned final judgment and order dated 15th March, 2023 rendered by the High Court of Judicature at Delhi in Writ Petition (C) No. 5478 of 2022, whereby the Division Bench thereof summarily dismissed the appellant's challenge to the vires of the Environmental Impact Assessment (Amendment) Rules, 2021 (hereinafter referred to as "the Impugned Rules"), promulgated vide Notification No. G.S.R. 456(E) dated 12th April, 2021, by the respondent No. 1, purportedly in exercise of powers conferred under Section 3 of the Environment (Protection) Act, 2005 (hereinafter "the Parent Act").
-
Learned Senior Counsel for the appellant, with characteristic erudition, has advanced a multi-pronged submission. The fulcrum of his argument rests on the premise that the Impugned Rules suffer from the vice of excessive delegation, transgressing the permissible legislative ambit delineated by the Parent Act. It is contended that Rule 5(b)(iii) of the Impugned Rules, which introduces a novel criterion for mandatory environmental clearance for projects below prescribed thresholds, effectively supplants the substantive provisions of Section M(2) of the Parent Act, rather than merely supplementing them. This, it is urged, amounts to an impermissible arrogation of essential legislative functions by the executive, a proposition anathema to the constitutional scheme of separation of powers, as expounded in In Re Delhi Laws Act, 1912 (AIR 1951 SC 332) and reiterated consistently thereafter, including in Hamdard Dawakhana (Wakf) Lal Kuan, Delhi v. Union of India (AIR 1960 SC 554).
-
Furthermore, it is strenuously canvassed that the Impugned Rules are vitiated by manifest arbitrariness, thereby infracting Article 14 of the Constitution. The classification engendered by the amended proviso to Rule 7, which exempts entities with a turnover below a specified threshold from the rigours of comprehensive environmental impact studies, is assailed as lacking an intelligible differentia bearing a rational nexus to the purported object of the Parent Act, namely sustainable development and environmental protection. Reliance is placed on Shayara Bano v. Union of India ((2017) 9 SCC 1) to buttress the contention that subordinate legislation, too, must withstand the test of non-arbitrariness.
-
Per contra, the Learned Additional Solicitor General, appearing for the Union of India, has robustly defended the vires of the Impugned Rules. It is posited that the delegation of power under Section 3 of the Parent Act is sufficiently guided, empowering the Central Government to frame rules for "carrying out the purposes of this Act." The Impugned Rules, it is submitted, are merely procedural and clarificatory, effectuating the legislative policy enshrined within the four corners of the Parent Act. The distinction carved out in the proviso to Rule 7 is asserted to be a reasonable classification based on economic capacity, aimed at obviating undue hardship for smaller entities, a permissible legislative device well-recognised in fiscal and regulatory statutes. The presumption of constitutionality attaching to subordinate legislation, it is averred, has not been dislodged by the appellant.
-
Upon a meticulous perusal of the statutory scheme, the legislative history of the Parent Act, and the precedents cited at the Bar, this Court is disinclined to accede to the appellant's submissions. The contours of permissible delegation are well-demarcated. While the legislature cannot delegate its essential legislative functions, it can empower the executive to formulate rules to carry out the statutory purpose, provided the legislative policy is adequately enunciated and a standard is laid down for the guidance of the delegate. In the instant lis, Section 3, when read harmoniously with the Preamble and the substantive provisions, particularly Sections L, M, and N of the Parent Act, provides a sufficiently discernible policy framework. Rule 5(b)(iii) does not, in our considered view, supplant Section M(2) but rather operationalises its intendment by prescribing a specific modality for compliance, which falls squarely within the domain of delegated legislation. The criterion introduced is not alien to the statutory objective but rather ancillary thereto.
-
The challenge predicated on Article 14 also fails to commend itself to us. It is trite that the legislature (and by extension, its delegate exercising rule-making power) enjoys considerable latitude in matters of classification. The onus is heavy upon the party assailing the classification to demonstrate that it is patently arbitrary, irrational, or devoid of any discernible principle. The differentiation based on turnover, as effected by the proviso to Rule 7, cannot, ipso facto, be branded as discriminatory or bereft of a rational nexus to the objective of facilitating compliance without imposing disproportionate burdens, particularly when viewed through the prism of administrative convenience and economic realities. The threshold prescribed does not appear, prima facie, to be whimsical or capricious.
-
In light of the foregoing analysis, we find no palpable constitutional infirmity or statutory transgression in the promulgation of the Impugned Rules warranting judicial interdiction. The High Court's declination to interfere was, therefore, justified.
-
The appeal is, accordingly, dismissed. No order as to costs.
ভাৰতৰ উচ্চতম ন্যায়ালয়ত
দেৱানী আপীল অধিকাৰক্ষেত্ৰ
দেৱানী আপীল নং XXXX/২০২৩
পোকো কৰ্পোৰেচন লিমিটেড ... আপীলকাৰী
বিৰুদ্ধে
ভাৰতীয় সংঘ আৰু অন্যান্য ... উত্তৰদাতা
বিচাৰ
[কৰাম: মাননীয় শ্ৰীযুত ন্যায়ামন্ত্ৰী কল্যাণ জ্যোতি সেনগুপ্ত, মাননীয় শ্ৰীমতী ন্যায়ামন্ত্ৰী অঞ্জলি গগনানী]
১. ভাৰতীয় সংবিধানৰ ১৩৬ নং অনুচ্ছেদৰ অধীনত দাখিল কৰা এই আপীলত দিল্লীৰ ন্যায়ালয়ে ২০২২ চনৰ ৫৪৭৮ নং ৰিট পিটিচীত (C) প্ৰদান কৰা ১৫ মাৰ্চ, ২০২৩ তাৰিখৰ চূড়ান্ত ৰায় আৰু আদেশৰ শুদ্ধতা আৰু আইনী স্থায়িত্বক প্ৰশ্ন কৰা হৈছে। এই ৰায়ত দিল্লীৰ ন্যায়ালয়ৰ বিভাগীয় বিচাৰপীঠে প্ৰতিবাদী নং ১-ৰ দ্বাৰা প্ৰকাশিত পৰিৱেশ প্ৰভাৱ মূল্যায়ন (সংশোধনী) বিধি, ২০২১ (ইয়াৰ পিছত "প্ৰশ্নযুক্ত বিধি" বুলি উল্লেখ কৰা হ'ব) ৰ বৈধতাৰ বিৰুদ্ধে দাখিল কৰা আপীলক সংক্ষিপ্তভাৱে খাৰিজ কৰি দিছিল। এই বিধি প্ৰতিবাদী নং ১-এ পৰিৱেশ (সুৰক্ষা) আইন, ২০০৫ (ইয়াৰ পিছত "মূল আইন" বুলি উল্লেখ কৰা হ'ব) ৰ ৩ নং ধাৰাৰ অধীনত প্ৰদান কৰা ক্ষমতাৰ প্ৰয়োগ কৰি প্ৰকাশ কৰিছিল।
২. আপীলকাৰীৰ বাবে আগবঢ়োৱা অভিজ্ঞ জ্যেষ্ঠ অধিবক্তাই নিজৰ পাৰদৰ্শিতাৰে এক বহু-মুখী যুক্তিত অৱতীৰ্ণ হৈছে। তেওঁৰ যুক্তিৰ মূল ভেটিটো হ'ল প্ৰশ্নযুক্ত বিধিসমূহে মূল আইনৰ দ্বাৰা নিৰ্ধাৰিত বৈধ বিধিবদ্ধ পৰিসৰ অতিক্ৰম কৰি অত্যাধিক প্ৰতিনিধিত্বৰ সমস্যাত ভুগিছে। ইয়াত দাবী কৰা হৈছে যে প্ৰশ্নযুক্ত বিধিৰ ৫(খ)(iii) বিধিয়ে নিৰ্ধাৰিত সীমাৰ তলৰ প্ৰকল্পসমূহৰ বাবে বাধ্যতামূলক পৰিৱেশগত অনুমোদনৰ বাবে এক নতুন মাপকাঠী প্ৰৱৰ্তন কৰিছে, যি মূল আইনৰ M(২) ধাৰাৰ মূল বিধানসমূহক কেৱল পৰিপূৰক কৰাৰ পৰিৱৰ্তে কাৰ্যকৰীভাৱে স্থানান্তৰিত কৰিছে। এইটোৱে কাৰ্যবাহীৰ দ্বাৰা অত্যাৱশ্যকীয় বিধিবদ্ধ কাৰ্যসমূহৰ এক অযোগ্য অধিকাৰ বুলি দাবী কৰে, যি ক্ষমতাৰ পৃথকীকৰণৰ সাংবিধানিক আঁচনিৰ বিৰুদ্ধে এক ঘৃণনীয় প্ৰস্তাৱ, যাক ইন ৰি দিল্লী লজ এক্ট, ১৯১২ (AIR 1951 SC 332) ত ব্যাখ্যা কৰা হৈছে আৰু তাৰ পিছত ধাৰাবাহিকভাৱে পুনৰাবৃত্তি কৰা হৈছে, লগতে হামদৰ্দ দাৱাখানা (ৱাকফ) লাল কুৱান, দিল্লী বনাম ভাৰতীয় সংঘ (AIR 1960 SC 554)-তো উল্লেখ আছে।
৩. তদুপৰি, ইয়াক জোৰ দি কোৱা হৈছে যে প্ৰশ্নযুক্ত বিধি সমূহ স্পষ্টভাৱে স্বেচ্ছাচাৰিতাৰে ভৰা, যাৰ ফলত সংবিধানৰ ১৪ নং অনুচ্ছেদ উলংঘা হয়। ৭ নং বিধিৰ সংশোধিত প্ৰ'ভিজ'ৰ দ্বাৰা সৃষ্টি হোৱা শ্ৰেণীবিভাজনে, যি নিৰ্দিষ্ট সীমাৰ তলৰ টাৰ্ণঅভাৰ থকা সত্তাসমূহক ব্যাপক পৰিৱেশ প্ৰভাৱ অধ্যয়নৰ কঠোৰতাৰ পৰা ৰেহাই দিয়ে, তাক মূল আইনৰ উদ্দেশ্য, অৰ্থাৎ বহনক্ষম উন্নয়ন আৰু পৰিৱেশ সুৰক্ষাৰ সৈতে এক যুক্তিসঙ্গত সম্পৰ্ক থকা বোধগম্য পাৰ্থক্যৰ অভাৱৰ বাবে সমালোচনা কৰা হৈছে। এই যুক্তিক শক্তিশালী কৰিবলৈ শায়ৰা বানো বনাম ভাৰতীয় সংঘ ((২০১৭) ৯ এছচিচি ১) ৰ ওপৰত নিৰ্ভৰ কৰা হৈছে যে অধীনস্থ আইনো স্বেচ্ছাচাৰিতাৰ পৰীক্ষাৰ সন্মুখীন হ'ব লাগিব।
৪. ইয়াৰ বিপৰীতে, ভাৰতীয় সংঘৰ হৈ হাজিৰ হোৱা শ্ৰীযুত অতিৰিক্ত ছলিচিটৰ জেনেৰেলে প্ৰশ্নযুক্ত বিধিৰ বৈধতাক শক্তিশালীভাৱে ৰক্ষা কৰিছে। ইয়াত কোৱা হৈছে যে মূল আইনৰ ৩ নং ধাৰাৰ অধীনত ক্ষমতা প্ৰতিনিধিত্ব যথেষ্ট নিৰ্দেশিত, যিয়ে কেন্দ্ৰীয় চৰকাৰক "এই আইনৰ উদ্দেশ্যসমূহ পূৰণ কৰিবলৈ" বিধি প্ৰস্তুত কৰিবলৈ ক্ষমতা প্ৰদান কৰে। দাখিল কৰা হৈছে যে প্ৰশ্নযুক্ত বিধি কেৱল প্ৰক্ৰিয়াগত আৰু স্পষ্টীকৰণমূলক, যিয়ে মূল আইনৰ চাৰিওফালে থকা বিধিবদ্ধ নীতি কাৰ্যকৰী কৰে। ৭ নং বিধিৰ প্ৰ'ভিজ'ত কৰা পাৰ্থক্যক অৰ্থনৈতিক ক্ষমতাৰ ওপৰত ভিত্তি কৰি এক যুক্তিসঙ্গত শ্ৰেণীবিভাজন বুলি দাবী কৰা হৈছে, যাৰ লক্ষ্য হৈছে সৰু সত্তাসমূহৰ বাবে অযথা কষ্ট দূৰ কৰা, যিটো এক বৈধ বিধিবদ্ধ সঁজুলি যাক বিত্তীয় আৰু নিয়ামক বিধি-বিধানত ভালদৰে স্বীকৃতি দিয়া হৈছে। অধীনস্থ আইনৰ সৈতে সংলগ্ন সাংবিধানিকতাৰ ধাৰণাটো আপীলকাৰীয়ে স্থানান্তৰিত কৰা নাই বুলি কোৱা হৈছে।
৫. বিধিবদ্ধ আঁচনি, মূল আইনৰ বিধিবদ্ধ ইতিহাস, আৰু বাৰত উল্লেখ কৰা পূৰ্ব উদাহৰণসমূহৰ এক নিখুঁত পৰ্যালোচনাৰ পিছত, এই আদালতে আপীলকাৰীৰ যুক্তিসমূহ মানি ল'বলৈ অনিচ্ছুক। বৈধ প্ৰতিনিধিত্বৰ ৰূপৰেখা ভালদৰে চিহ্নিত কৰা হৈছে। যদিও বিধানমণ্ডলে ইয়াৰ অত্যাৱশ্যকীয় বিধিবদ্ধ কাৰ্যসমূহ প্ৰতিনিধিত্ব কৰিব নোৱাৰে, তথাপিও ই কাৰ্যবাহীক বিধিবদ্ধ উদ্দেশ্য পূৰণ কৰিবলৈ বিধি প্ৰস্তুত কৰিবলৈ ক্ষমতা প্ৰদান কৰিব পাৰে, যদিহে বিধিবদ্ধ নীতি পৰ্যাপ্তভাৱে উল্লেখ কৰা হয় আৰু প্ৰতিনিধিৰ নিৰ্দেশনাৰ বাবে এক মানদণ্ড নিৰ্ধাৰণ কৰা হয়। এই গোচৰত, ৩ নং ধাৰা, মূল আইনৰ প্ৰস্তাৱনা আৰু মূল বিধানসমূহৰ সৈতে সামঞ্জস্যপূৰ্ণভাৱে পঢ়িলে, বিশেষকৈ L, M, আৰু N ধাৰাসমূহে এক পৰ্যাপ্তভাৱে বোধগম্য নীতিৰ কাঠামো প্ৰদান কৰে। আমাৰ বিবেচনা অনুসৰি ৫(খ)(iii) বিধিয়ে M(২) ধাৰাক স্থানান্তৰিত নকৰে, বৰঞ্চ ইয়াৰ উদ্দেশ্যক পালনৰ বাবে এক নিৰ্দিষ্ট পদ্ধতি নিৰ্ধাৰণ কৰি কাৰ্যকৰী কৰে, যি প্ৰতিনিধিত্ব কৰা আইনৰ ক্ষেত্ৰখনৰ ভিতৰত পৰে। প্ৰৱৰ্তন কৰা মাপকাঠী বিধিবদ্ধ উদ্দেশ্যৰ পৰা পৃথক নহয়, বৰঞ্চ ইয়াৰ সহায়কহে।
৬. ১৪ নং অনুচ্ছেদৰ ওপৰত ভিত্তি কৰি কৰা প্ৰত্যাহ্বানটোৱেও আমাৰ ওচৰত নিজকে প্ৰশংসা কৰিবলৈ ব্যৰ্থ হৈছে। এইটো এটা সাধাৰণ কথা যে বিধানমণ্ডলে (আৰু ইয়াৰ দ্বাৰা, নিয়ম প্ৰণয়ন কৰাৰ ক্ষমতা প্ৰয়োগ কৰা প্ৰতিনিধিয়ে) শ্ৰেণীবিভাজনৰ বিষয়ত যথেষ্ট স্বাধীনতা উপভোগ কৰে। শ্ৰেণীবিভাজনক প্ৰত্যাহ্বান জনোৱা পক্ষৰ ওপৰত ইয়াৰ স্পষ্ট স্বৈৰাচাৰিতা, অযৌক্তিকতা, বা কোনো বোধগম্য নীতিৰ অভাৱ আছে বুলি প্ৰমাণ কৰাৰ ভাৰ যথেষ্ট। ৭ নং বিধিৰ প্ৰ'ভিজ'ৰ দ্বাৰা প্ৰভাৱিত টাৰ্ণঅভাৰৰ ওপৰত ভিত্তি কৰি কৰা পাৰ্থক্যক, স্বতঃস্ফূৰ্তভাৱে, বৈষম্যমূলক বুলি চিহ্নিত কৰিব নোৱাৰি বা আনুপাতিক বোজা নথকাকৈ পালনক সহজ কৰি তোলাৰ উদ্দেশ্যৰ সৈতে এক যুক্তিসঙ্গত সম্পৰ্কৰ অভাৱ বুলি ক'ব নোৱাৰি, বিশেষকৈ যেতিয়া ইয়াক প্ৰশাসনিক সুবিধা আৰু অৰ্থনৈতিক বাস্তৱতাৰ দৃষ্টিভংগীৰে চোৱা হয়। নিৰ্ধাৰিত সীমাটো প্ৰথম দৃষ্টিত খেয়ালিপনা বা খামখেচী যেন নালাগে।
৭. পূৰ্বৰ বিশ্লেষণৰ পোহৰত, আমি প্ৰশ্নযুক্ত বিধি প্ৰণয়নত কোনো স্পষ্ট সাংবিধানিক দুৰ্বলতা বা বিধিবদ্ধ উলংঘা বিচাৰি পোৱা নাই যি ন্যায়িক নিষেধাজ্ঞাৰ বাবে উপযুক্ত। সেয়েহে, উচ্চ ন্যায়ালয়ে হস্তক্ষেপ নকৰাৰ সিদ্ধান্তটো ন্যায্য আছিল।
৮. সেই অনুসৰি, আপীলখন খাৰিজ কৰা হ'ল। খৰচৰ কোনো নিৰ্দেশ নাই।
Translating code files while protecting syntax
Translating code files requires distinguishing between executable code and human-readable text, such as comments or documentation. We find that Sarvam-Translate selectively translates natural language content while leaving code unchanged. For example, the comment "Function to perform Bubble Sort" is translated in Bengali as "বাবল সর্ট করার ফাংশন" retaining technical terms like bubble sort without undue complicated translation.
Input
#include <iostream>
#include <vector>
// Function to perform Bubble Sort
void bubbleSort(std::vector<int>& arr) {
int n = arr.size();
// Outer loop for each pass through the array
for (int i = 0; i < n - 1; i++) {
bool swapped = false; // Flag to check if any elements were swapped in this pass
// Inner loop for comparing adjacent elements
for (int j = 0; j < n - i - 1; j++) {
// If the current element is greater than the next, swap them
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
swapped = true; // Set flag to true if a swap occurred
}
}
// If no swaps occurred in this pass, the array is already sorted
if (!swapped) {
break;
}
}
}
// Utility function to print the elements of the array
void printArray(const std::vector<int>& arr) {
for (int num : arr) {
std::cout << num << " ";
}
std::cout << std::endl;
}
// Main function
int main() {
std::vector<int> data = {64, 34, 25, 12, 22, 11, 90};
std::cout << "Original array: ";
printArray(data);
// Call bubble sort function
bubbleSort(data);
std::cout << "Sorted array: ";
printArray(data);
return 0;
}
#include <iostream>
#include <vector>
// বাবল সর্ট করার ফাংশন
void bubbleSort(std::vector<int>& arr) {
int n = arr.size();
// অ্যারের প্রতিটি পাসের জন্য বাইরের লুপ
for (int i = 0; i < n - 1; i++) {
bool swapped = false; // এই পাসে কোনো উপাদান অদলবদল হয়েছে কিনা তা পরীক্ষা করার ফ্ল্যাগ
// সন্নিহিত উপাদানগুলির তুলনা করার জন্য ভিতরের লুপ
for (int j = 0; j < n - i - 1; j++) {
// যদি বর্তমান উপাদানটি পরবর্তী উপাদান থেকে বড় হয়, তবে তাদের অদলবদল করুন
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
swapped = true; // যদি কোনো অদলবদল ঘটে থাকে তবে ফ্ল্যাগটিকে সত্য সেট করুন
}
}
// যদি এই পাসে কোনো অদলবদল না ঘটে থাকে, তবে অ্যারেটি ইতিমধ্যেই সাজানো হয়েছে
if (!swapped) {
break;
}
}
}
// অ্যারের উপাদানগুলি মুদ্রণ করার ইউটিলিটি ফাংশন
void printArray(const std::vector<int>& arr) {
for (int num : arr) {
std::cout << num << " ";
}
std::cout << std::endl;
}
// মূল ফাংশন
int main() {
std::vector<int> data = {64, 34, 25, 12, 22, 11, 90};
std::cout << "Original array: ";
printArray(data);
// বাবল সর্ট ফাংশন কল করুন
bubbleSort(data);
std::cout << "Sorted array: ";
printArray(data);
return 0;
}
Given the generic abilities of the model, we believe new use-cases can be unlocked. We encourage you to try Sarvam-Translate and share your findings with us on social media or our
discord.
In the remainder of this blog, we will go through some technical details in terms of evaluation and training of the model.
Automatic Evaluation on Structured Content
To test the abilities of Sarvam-Translate, we conducted a large-scale evaluation that spans multiple languages, document styles, and content formats. For this evaluation, we used a curated dataset of articles covering a range of real-world formats and content types. The dataset included GitHub Markdown files, scanned PDFs that were digitized into Markdown using Vision-Language Models (VLMs), documents containing mathematical equations written in LaTeX, and chemistry documents featuring complex chemical notations. It also incorporated code files with embedded comments and documentation, as well as web page content extracted from HTML. We created 1,000 documents in each of these categories.
Given the scale of the evaluation, conducting human reviews for every document type and language pair would be impractical. To address this, we used Gemini Flash 2.5 to perform automatic evaluations. For each document type, we designed prompts that direct Gemini to focus on the specific aspects of translation quality that matter most for that format. For example, the evaluation criteria for math equations differ from those for code or HTML. We describe these criteria below.
Markdown Content (GitHub)
Goal: Ensure that the translated document preserves the Markdown structure including headings, bullet points, links, code blocks, and that the translated content fits naturally within the structure. The formatting should remain exactly as in the source.
Digitized Markdown (VLM / OCR output)
Goal: Evaluate how robust the translation is when the source document comes from a digitized, OCR-extracted source which may contain slight errors or inconsistencies. The structure (tables, headings) should be preserved, and the translation should handle noise gracefully without introducing additional errors.
Math Content (LaTeX equations)
Goal: Ensure that LaTeX equations are preserved exactly in the translated document, while surrounding text is translated naturally. No part of the equation syntax should be altered or corrupted. The translation must maintain the integrity of mathematical notation.
Chemistry Content (Equations, Symbols)
Goal: Validate that chemical equations, including subscripts, superscripts, arrows, and special symbols, are retained correctly. The text around the equations should be translated naturally, while chemical notations should remain untouched and precisely formatted.
Code Content (Code with Comments)
Goal: Ensure that code remains exactly the same in the translated document, and that only the comments and documentation are translated. The programming syntax must not be altered. The evaluation should also check that no unintended changes (indentation, special characters) were introduced.
HTML Content (Web pages)
Goal: Verify that HTML tags and structure are preserved exactly. The visible text content within the tags should be translated fluently, but the HTML itself should remain unchanged. If certain elements (e.g. italics, bold) are present in the original, the corresponding translation should maintain the same styling.
Evaluation Results
Translation quality scores (scale of 5) across languages, averaged over multiple content types.
Human Evaluations
While automatic evaluations are useful at scale, human evaluations are necessary given the subjectivity of translation quality and limited abilities of frontier models in specific languages. To do this, we curated 100 English documents covering a diverse mix of content types, including technical material such as scientific, mathematical, and chemistry-based content; informal and spoken text drawn from speech transcripts and conversational blogs; structured content such as Markdown documents, HTML pages, and code snippets; and formal content like news articles and textbook excerpts.
These documents were translated using Sarvam-Translate, as well as with leading open-source LLMs, such as Gemma3-27B-IT, Llama-3.1-405B-FP8 and Llama4 Scout. The translated outputs were then evaluated by professional human annotators. The evaluators were professional language experts, each with multiple years of professional experience in translation creation and validation, and with deep proficiency in both English and their target Indian language.
The human evaluators assessed the translations on several key dimensions, including fluency, adequacy, faithfulness to the source structure, and inclusivity. They were shown two translations at random and asked to pick if one is more preferred or both are equally preferred. The results of the human evaluation are summarised in the following tables.
Gemma3 27B ITvs Sarvam Translate
Llama 4 Scout vs Sarvam Translate
Llama 3.1 405B FP8 vs Sarvam Translate
Across all Indian languages, Sarvam-Translate consistently outperformed other models, particularly in its ability to handle structured content, maintain coherence over longer contexts, and deliver inclusive and culturally sensitive translations.
How Sarvam-Translate was trained
This journey has been years in the making, built on sustained effort and deep expertise in developing Indian language technologies in the open source. We invested heavily in building robust data-cleaning pipelines and sophisticated annotation workflows to ensure the highest quality datasets. We also leveraged the Gemma 3 open-source models which provided the best starting point to build Sarvam-Translate in comparison to any other model.
Data
Sarvam-Translate was trained on a rich and diverse dataset of translation pairs between English and 22 Indian languages. This dataset combines multiple sources. First, we incorporated cleaned data from past open-data efforts, including BPCC, which itself contains both mined and manually validated data. We carefully cleaned this data using robust internal pipelines. Second, we generated new translation pairs from carefully curated English source content. This spanned a wide range of domains: scientific and historical content, conversational and modern text, and structurally complex formats such as code, LaTeX, HTML, and chemistry equations. In this process, we recognised the need for very high quality filters on the data. Even large models such as Llama-3.1-405B-FP8make many errors in generating output in Indian languages.
Training Process
We trained Sarvam-Translate on top of Gemma3-4B-IT. We fine-tuned this in a two-stage process. In the first stage, we fine-tuned the full model on a larger dataset with broad coverage, including some noisier but domain-diverse data to establish wide-ranging translation capability. This is also required to provide language ability to the model in languages it is not already fluent in. In the second stage, we used LoRA to fine-tune the model further on a smaller, highly curated, format-diverse dataset, paying careful attention to format preservation and style consistency. Through various ablations we found this two-stage process to be effective.
Inference Efficiency
We were able to quantise Sarvam-Translate using Post-Training Quantization (PTQ), leveraging a large and diverse calibration dataset to ensure robust 8-bit inference performance. The inference system is finely tuned to run on NVIDIA NIM with the TensorRT engine, utilising full FP8 kernels for improved throughput and efficiency. This optimised set up is available for use in our API store and can be tried in the dashboard.
Known Limitations
While this model supports 22 languages across a variety of tasks, performance can vary depending on the language. These differences stem from the balance of pre-training data, post-training resources, and each language’s representation in the tokeniser. Document translation is a key capability, but performance is more limited for certain languages such as Bodo, Dogri, Kashmiri, Manipuri, Santali, Sanskrit, and Sindhi, where we have observed lower translation quality and occasional incomplete outputs.
For better-supported languages, the model performs well on most document formats. However, it has not been extensively trained on long-form LaTeX or HTML documents. As a result, it may sometimes miss tags or other structural elements in very large .tex files or .html files. To maintain accuracy, we recommend splitting large files of code or latex into smaller sections and then translating individual sections, when possible.
In addition, we have infrequently observed that some outputs may include transliterations or code-mixed segments, particularly in low-resource or highly inflected languages.
Conclusion
Translation technology has progressed substantially over the past few years. With Sarvam-Translate, we extend these advancements to 22 Indian languages, ensuring their representation across a wide range of content types.
What makes this achievement especially meaningful is the model’s ability to handle real-world, mixed-format documents such as Markdown, HTML, scientific notation, code, and more. The model not only preserves structure but also respects context, style, and gender nuances, ensuring that every translation feels authentic and natural.
We believe that this is a key enabler for:
- Making the web more accessible in Indian languages
- Supporting education and research in native languages
- Empowering government and public services to reach citizens in their preferred language
- Catalyzing the creation of Indian language digital content at scale
This is just the beginning. As content formats continue to evolve, our mission remains the same: to ensure that Indian languages are well-represented in the digital landscape.
We remain committed to advancing this work through collaboration with the open-source community, researchers, industry, and government partners, making high-quality translation accessible for all 22 Indian languages.
We invite you to explore Sarvam-Translate, try it out, give us feedback, and join us in shaping the next frontier of Indian language technology.
Curious what else we're building? Explore our APIs and start creating.
Curious what else we're building?
Explore our APIs and start creating.