
Saaras V3
Speech to Text API
for Indian Languages
Transcribe noisy audio with the lowest word error rates across 22 Indian languages. Real-time streaming, native code-switching, speaker diarization.
from sarvamai import Sarvam client = Sarvam(api_key="YOUR_API_KEY") # Transcribe audio to text response = client.speech.transcribe( file=open("audio.wav", "rb"), language_code="hi-IN", model="saaras:v3", ) print(response.transcript)
Try it live
Or try a sample
Record or pick a sample to see the transcript here.
Trusted by leading teams















Production-grade automatic speech recognition
Handles noise, accents, and code-switching. Go live in under 30 minutes.

Streaming-first architecture
Sub-150ms time to first token. Configurable Accurate, Balanced, and Fast modes for every latency requirement.
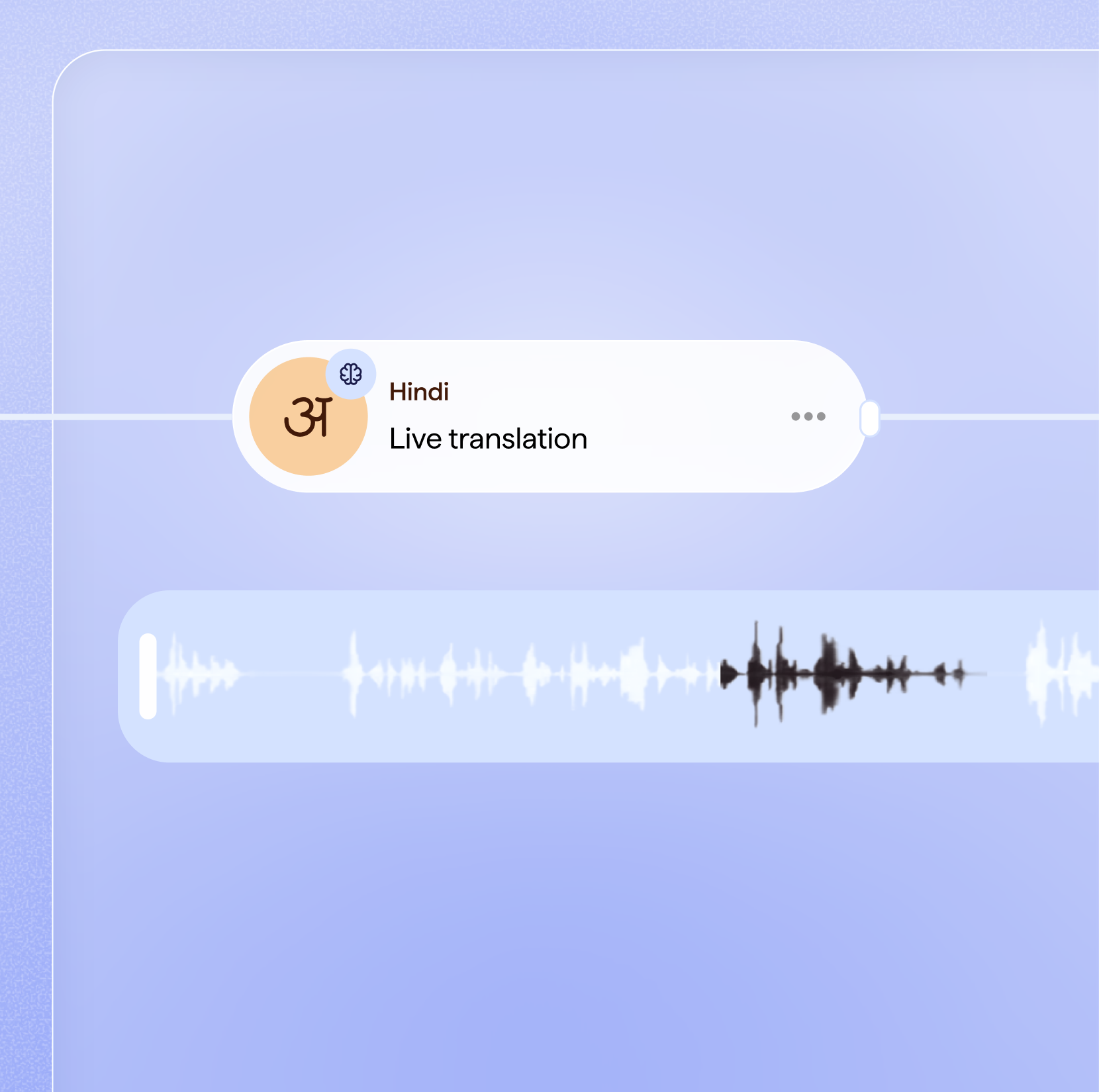
Code-switching & noise robust
Trained on 1M+ hours of real-world audio. Handles code-mixed speech, noisy telephony, and diverse accents.

Drop-in SDKs
Go live in under 10 minutes with official Python and Node.js SDKs. Pipecat & LiveKit ready.
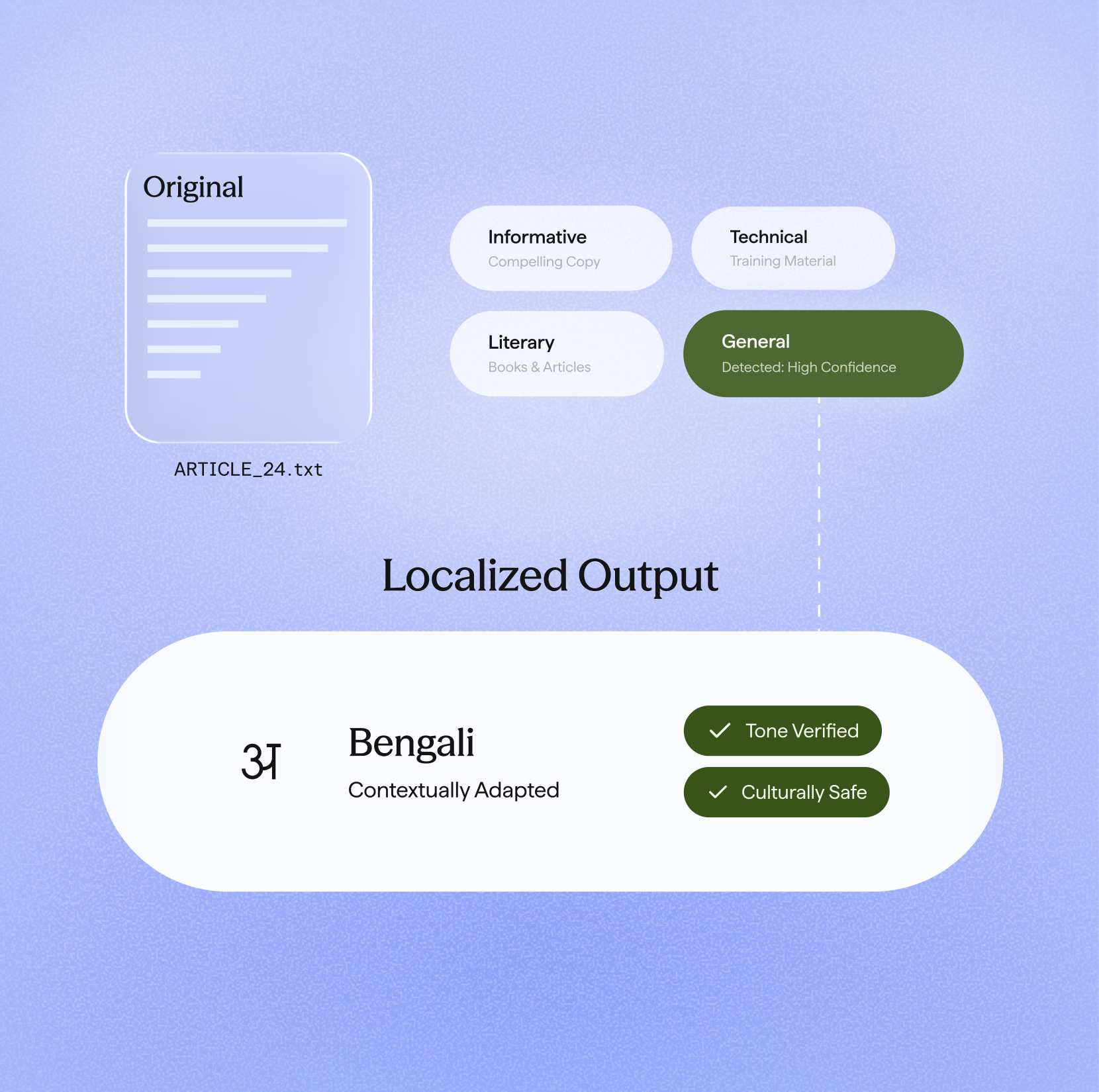
23 Indian languages
All 22 scheduled languages plus English. Unified multilingual model with automatic language detection.

Beyond raw transcripts
Speaker diarization, word-level timestamps, output format control, and automatic language detection built in.
Streaming-first architecture
Sub-150ms time to first token. Configurable Accurate, Balanced, and Fast modes for every latency requirement.
Code-switching & noise robust
Trained on 1M+ hours of real-world audio. Handles code-mixed speech, noisy telephony, and diverse accents.
Drop-in SDKs
Go live in under 10 minutes with official Python and Node.js SDKs. Pipecat & LiveKit ready.
23 Indian languages
All 22 scheduled languages plus English. Unified multilingual model with automatic language detection.
Beyond raw transcripts
Speaker diarization, word-level timestamps, output format control, and automatic language detection built in.
Battle-tested at scale
Saaras v3 runs in production across call centers, voice agents, and live applications.
Works with your stack
Plug Sarvam ASR into LiveKit, Pipecat, n8n, and more.
Enterprise-ready. Data stays in India.
Compliance, control, and data sovereignty. Not bolted on. Built in from day one.
No training on your data
Your API inputs are never used for model training. Zero data retention after processing unless you explicitly request it.
- Data deleted after processing by default
- Opt-in retention with configurable TTL
- Separate data and model training pipelines
- Full DPDP compliance
Deploy on your terms
All processing happens within India. No cross-border transfers. For regulated workloads, we support VPC and on-premise deployment.
- India-only data processing
- VPC and on-premise options
- Consent-based voice cloning
- Content safety filters built in
Security and governance
Every API call is logged and traceable. Role-based access, audit trails, and data residency controls built into the platform.
Base plan
Free trial included
No credit card required. Get API keys instantly.
Frequently asked questions
Start building with India's best speech recognition. Get API keys in 30 seconds.
Start building with India's best speech recognition.
Get API keys in 30 seconds.