What is speech to text?
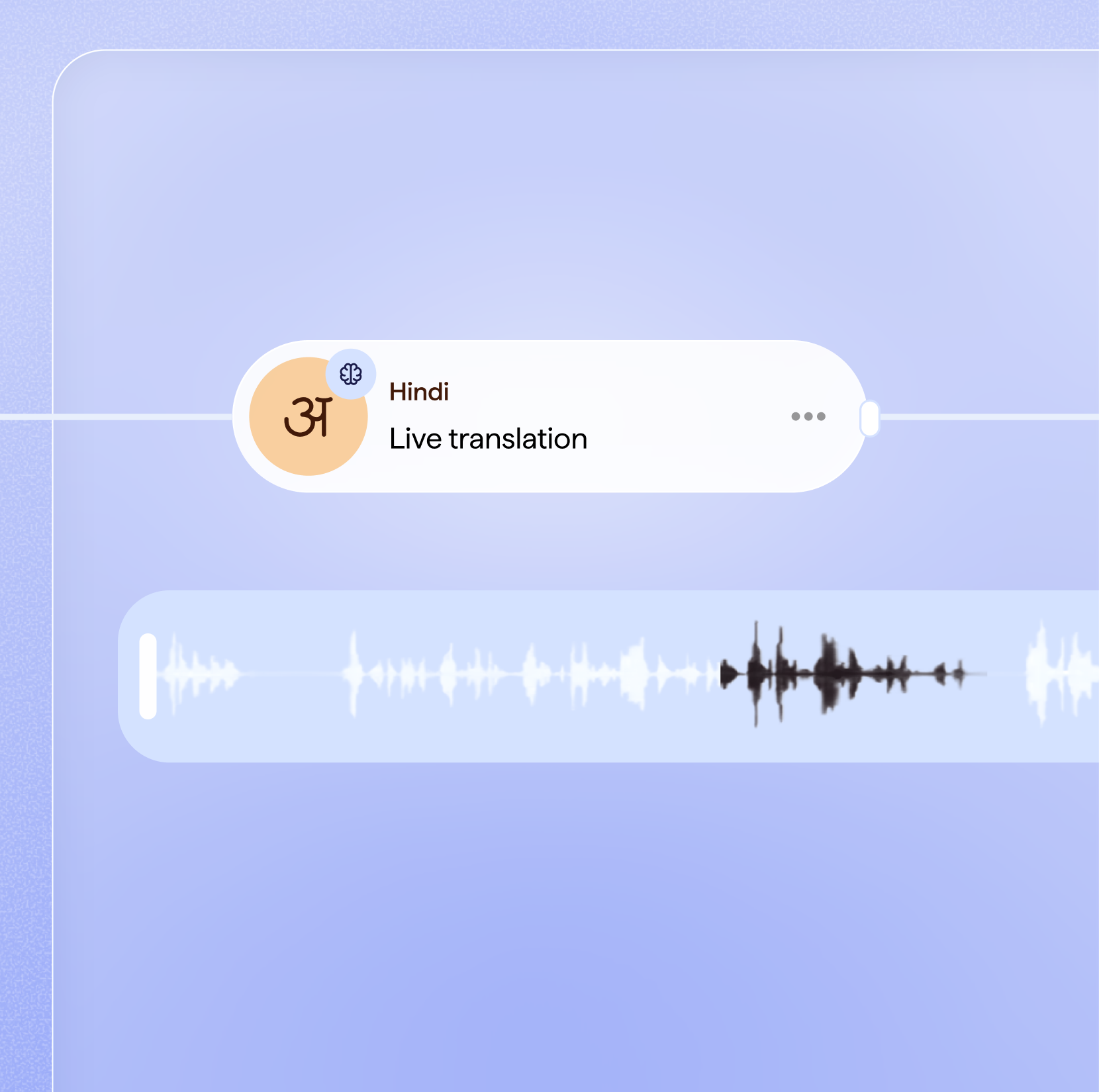
Speech to text (STT), also called voice to text, audio to text, or automatic speech recognition (ASR), converts spoken audio into written text using AI. Feed it a phone call, a meeting recording, a voice note, or a live broadcast, and it produces a transcript in real time or after the fact. Modern voice recognition systems use deep neural networks and can handle accents, background noise, multiple speakers, and mid-sentence language switching.
Indian languages are where English-centric models fall apart. Hindi speakers routinely switch to English and back within a single sentence. Tamil is agglutinative, meaning a single word can encode what English needs a full phrase for, which makes word boundary detection much harder. Telugu and Kannada share Dravidian roots but have distinct phonetic systems. And Indian telephony audio is often 8kHz with heavy background noise, nothing like the clean studio recordings global ASR models are optimized for. A voice to text converter that treats these as edge cases will not work in production.
Sarvam started from Indian audio, not English. Saaras v3, the model behind Sarvam's speech to text converter, was trained on over 1 million hours of real Indian speech through a 4-stage pipeline: large-scale pre-training, supervised fine-tuning, reinforcement learning, and post-training for long-tail errors. It achieves 19.31% WER on the IndicVoices benchmark across 10 languages (down from 22% in v2), and outperforms GPT-4o Transcribe, Gemini 3 Pro, Deepgram Nova3, and Scribe v2 on Indian language accuracy. For Indian-accented English, Sarvam validated on the Svarah benchmark (9.6 hours, 117 speakers across 65 districts in 19 Indian states). Whether you need speech to text for Hindi, speech to text for Tamil, or any of the other 20 supported languages, Saaras v3 is the best-performing option on the benchmarks that matter.