

Understand every document,
in every major Indian language
Extract text, tables, and structure from documents with remarkable precision, especially in Indian languages.
Sarvam Vision
Examples
have knowledge of some vacant "Consulate" or "Special Service", that my Record and Endorsements would warrant my filling to the advantage of the Government
A Knowledge of your Selection and appointment of Such only as are most fitting for the place regarded of politics or local influence has prompted me you and myself to look to you Mr President for that just consideration we have failed to secure at other hands,
With the assurance of two having their Countrys welfare more at heart than their own personal interest believe us Mr President
Your Obt Servants
Wm H. Young and native of Erie County New York Wife F Rowland Young native of St Markes Florida
address P.O. box 565 Washington DC

From documents to usable data
Hover or tap on any example to see it in action.

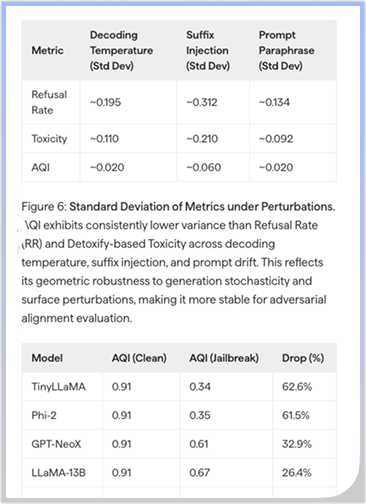
Visual reasoning
Understand charts, diagrams, and infographics across 23 languages. Interprets visual context, not just text.


Knowledge extraction
Go beyond OCR. Extract trend data, preserve nested tables, and handle complex layouts precisely.


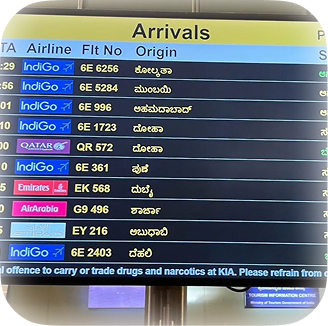

In-the-wild OCR
Read signboards, street scenes, and real-world documents across Indian scripts with image perception.



Powering real-world document
workflows
Document digitisation
Convert scanned documents, PDFs, and legacy archives into structured, searchable digital formats across all Indian languages.
Government records & archives
Academic papers & textbooks
Legal documents & contracts
Historical & cultural manuscripts

Built for Indian documents
Production-grade Document Digitisation with structured outputs, async processing, and enterprise-ready APIs.
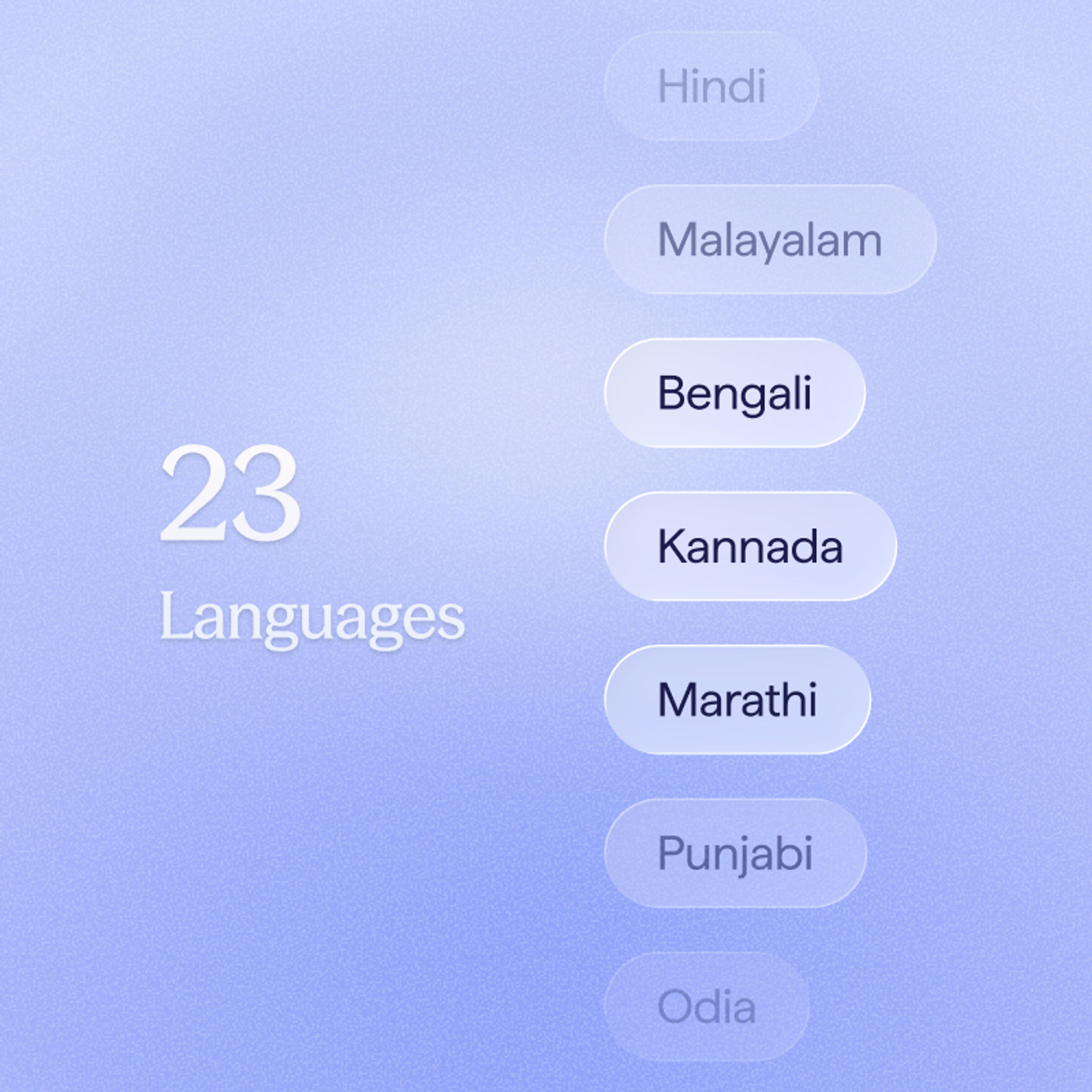
23 languages with native Indic script support
All 22 scheduled Indian languages plus English, with accurate script recognition across every script family.

PDF, PNG, JPG & ZIP input
Process any document format. Single pages or bulk archives.

Accurate table extraction
Handles merged cells, multi-level headers, and invisible borders perfectly.

HTML & Markdown output
Clean, structured output ready for downstream processing.
Async job-based API
Upload, process, and download. Designed for large documents and batch workflows.
State-of-the-art Document Digitisation
Leading performance on global benchmarks.
olmOCR: Overall Performance
Score (%) · Higher is better
23 languages, every script natively understood
Developer-first platform
OpenAI-compatible APIs. Drop-in SDKs for Python and Node.js. Go from zero to first extraction in under 5 minutes.
REST & WebSocket APIs
Standard REST for batch processing, WebSocket for real-time streaming with low-latency responses.
SDKs & libraries
Official Python and Node.js SDKs with TypeScript support. pip install sarvam-ai.
Complete documentation
Interactive API reference, code samples, and integration guides for every endpoint.
Free tier included
Start building immediately. No credit card, no sales call, no minimum commitment.
from sarvamai import SarvamAI client = SarvamAI(api_subscription_key="YOUR_SARVAM_API_KEY") # Digitize a document response = client.document_digitization.digitize( file_path="invoice.pdf", language="en-IN", output_format="md" ) # Access extracted content for page in response.pages: for block in page.blocks: print(f"[{block.layout_tag}] {block.text}")
Base plan
Free trial included
No credit card required. Get API keys instantly.
Your questions, answered
Start extracting in minutes
Start extracting in minutes